
Here are the questions we most frequently get and the answers we most frequently give:
What is active learning?
Active learning is a semi-supervised machine learning strategy. Generally speaking, active learning aims to reduce the amount of labeled data required to train an effective model. AL models do this by first learning from a random sampling of data, after which the model actively requests more specific types of labels to improve its performance. This leads to converging an optimal model faster using less data.
So it helps reduce labeling costs?
Among other things, yes! A lot of data we use to train models is either of minimal value (think duplicative data) or is actually harmful (think of mislabeled or spammy data). Training models with a lot of useless or detrimental data reduces their efficacy. Active learning seeks to solve that problem.
Aren’t there other solutions to reduce labeling costs?
There are, yes. Labeling costs are a real issue for a lot of businesses, either because of the volume of their typical dataset or because getting quality labels is slow or expensive (think of something where the labels need to come from experts like surgeons, lawyers, geophysicists, etc.). Labeling is also expensive because you often need to label data more than once. Of course, crowdsourced labeling has helped for some of us, but some companies don’t want to share data with third parties or simply cannot because of privacy concerns (or the data requires expertise the crowd doesn’t have).
Here are a couple of solutions you may be familiar with:
– Human-in-the-loop: Here, you might see machines label the “easy” parts and keep humans to take care of the corner cases. Letting machines do a first pass and keeping human annotators as reviewers and correctors is another strategy.
– Snorkel: Snorkel’s an algorithm a lot of people are familiar with and it does work quite well for certain problems. Here, you use a group of people to generate standardized rules to generate labels. Think having people note what kind of content is offensive and using that input to create rules around racist language, bullying, or offensive speech.
Of course, there are issues with these approaches. For example, both still require you to label a ton of data (more efficient though they may be), which is often a waste of time and money.
Our approach at Alectio is different because we’re interested in finding and prioritizing the most useful data for your models to ingest. This solves the issues around labeling bottlenecks, overfitting, compute resources, and more since you label less data but label the right data for your project.
Does active learning use more compute resources than “regular” supervised learning?
Active learning was originally developed to help people save on labeling costs, not compute resources. That means that yes, it can use more computer resources than “regular” supervised learning. That said, active learning can actually help reduce your consumption of compute resources if your number of training loops isn’t too high.
Okay, so Alectio is an active learning company?
We definitely leverage active learning here at Alectio, but we combine it with reinforcement learning, meta learning, information theory, entropy analysis, topological data analysis, data shapley, and more. That’s because active learning in and of itself isn’t enough to get you the results you need. And as we mentioned in our last answer, active learning was originally designed to reduce labeling costs but generally will not reduce the compute power you use or the training time your problem requires. Combining it with other methods and concepts helps keep those in check.
So why isn’t active learning used more in the industry?
Largely because people are most familiar with a certain kind of active learning where the model selects least-confident data to train on. This works in academia, where the data is clean and the labels are accurate, but in the real world where data can be messy, this strategy doesn’t work. You can read more about that here.
I’m stuck on the idea that less data can lead to better performance and higher accuracy. I’ve always heard more data was always better.
That’s definitely a pervasive belief. But remember something we said up above: all data is not created equal. Some of it is really useful for model training. Some of it less so (redundant data, for example, can cause overfitting). Some of it is actively harmful (mislabeled data, for example, can cause serious confusion). Think about it like this curve:
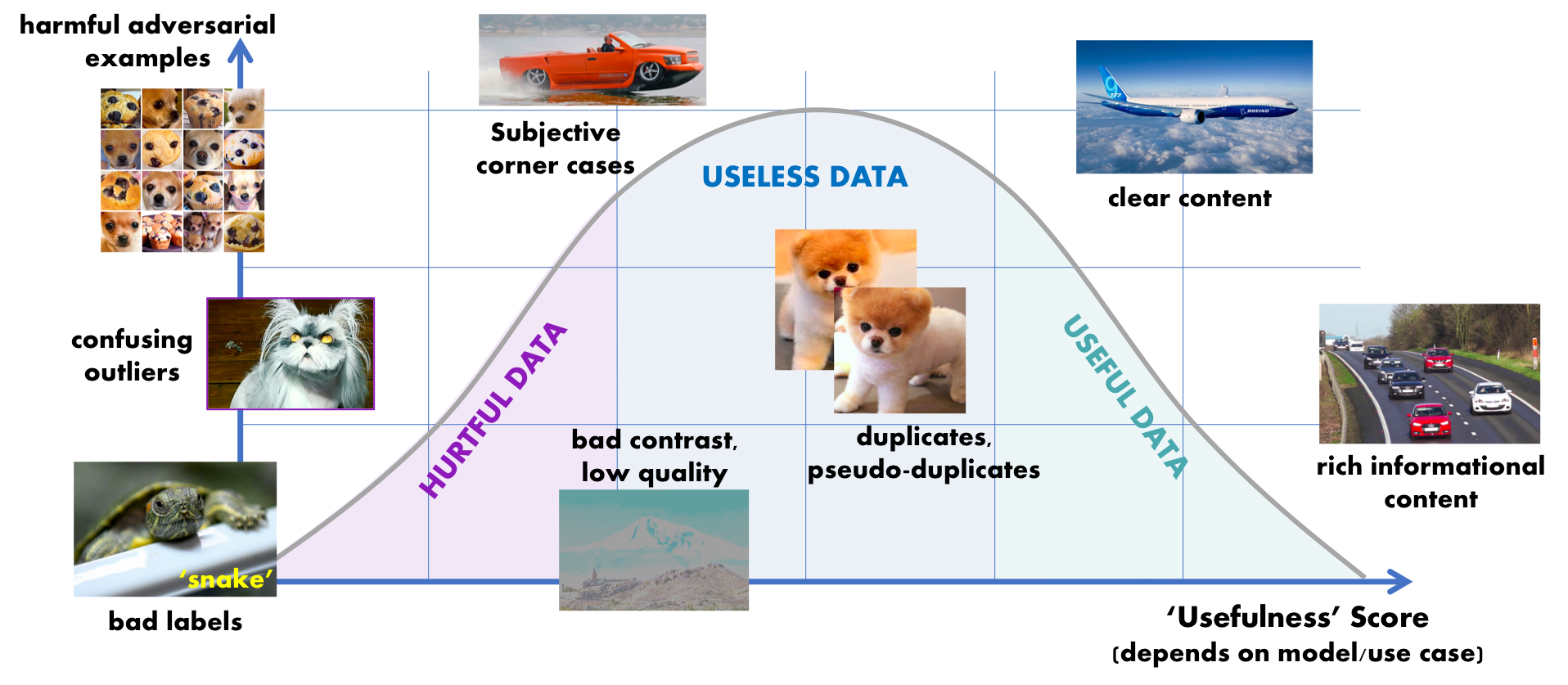
You want to prioritize training the model with data from the right, not the middle or the left.
So why should I consider Alectio to do my active learning?
Because it’s not easy to find and build the right querying strategy and most of the writing out there is on academic datasets that don’t mirror the data businesses actually have.
In fact, a few years back, a lot of people said deep learning didn’t work because they’d tried and failed at it but a big reason they failed was because nobody was really tuning their hyperparameters properly. At Alectio, we’re providing automated hyperparameter tuning for active learning and believe that will lead to much more widespread adoption.
What kind of data do you work with?
Although we write a lot about image data, that’s largely just because it’s easier to represent online and explain. We can work with virtually any data type because our tech learns from the metadata (log files) generated from the training process itself.
Will Alectio help me with feature engineering?
Our technology identifies which records are the most impactful and useful to a model, not which features should be used in a model. That said, since we can identify which data is useless to a learning process, it can occasionally be used to find weaknesses in the model itself, which can in turn help with feature engineering.
What if I don’t have a model yet or I’m still developing it?
In most situations, usefulness is actually a function of the use case and the data versus the model itself. Think about a facial recognition problem. Regardless of if you’ve selected a model, data without a person in it or with bad resolution is going to be less useful than other data. We can uncover that without knowing what model you’re using.
So data usefulness isn’t model-specific?
Usually not! Our research shows that usefulness is data-specific, not model-specific. For example, data uselessness is usually due to either redundancy or irrelevance, and while irrelevance is use case specific, redundancy is a more general concept. Data hurtfulness is also fairly use case agnostic. You can read a bit more about that here.
Would you call Alectio a data labeling company?
Nope. Though we know a lot about labeling, we don’t have crowds of human labelers. We tell you which data should be labeled or can work directly with your labeling vendor.
So I can use human-in-the-loop to curate my data?
Of course! Many companies have dedicated teams focused on data curation these days. The issue is that people don’t understand how models work, especially black box models like deep learning. Having them decide which data matters often amounts to wild guessing and can inject biases into your data. At Alectio, we sometimes say we give the model a voice. It decides what data it needs to learn.
Okay, sum it up for me.
Alectio uses an ensemble strategy that includes active learning to figure out the most valuable data points in your dataset. Regardless of what model you’re using, we can forecast what data will be useful to label, what data doesn’t really matter, and what data is harmful. Using that information, you use less data to converge on optimal performance.



0 Comments