

Last piece, we dug into the concept of increasing access to AI. In this one, we’re going to tackle opportunity. You may be asking yourself what exactly the difference is here, and, we’ll admit this a Venn diagram with some overlap. Diverse data labeling, for example, increases both access to AI understanding and allows underserved populations to have a hand in training models that can and will affect each of us.
But opportunity is different than accessibility. Opportunity’s goal is to flatten disparities in our field. Responsible AI requires that we’re actively — not passively — reaching out to people currently shut out of or ignored in our field.


The thing we like best about this category and this distinction is it’s something each of us can help promote by doing a few simple things. Let’s get started:
Conscientious community building
A few years back, I attended an Open Data Science Conference at a San Francisco hotel. Like most conferences, there were vendor booths, informative panel discussions, and mediocre coffee. But there was an anecdote around bias in one of the talks that seems like a good starting place here.
The story itself was around autonomous vacuum cleaners — -think something like a Roomba. Of course, the AI in these vacuum cleaners isn’t exactly the most groundbreaking stuff but they’ve been trained to avoid staircases, remember routes around rooms, identify obstacles, estimate room size and so on. If you’ve owned one of these, you know they have their quirks and nuances but they work well enough. That is, unless you lived in Thailand.


See, in Thailand, it’s far more common for people to sleep on thin mats on the floor. In fact, plenty of cultures around the world sleep this way more often than Westerners do. The problem was, the vacuum cleaner never saw this data. That meant that if it was running while someone was asleep, the vacuum had this bad habit of, well, sucking up people’s hair while they slept.
This happened, of course, because the vacuum had simply not encountered this. It was trained on data that didn’t have enough (or any) instances of people sleeping on the floor and so it just kind of rolled on over and woke people up in what you’d imagine was a startling and vaguely painful way. The question we need to ask ourselves is if this would’ve happened if you’d had any Thai engineers in the room during training.
This is, admittedly, a bit of a silly example but it underscores the importance of diversity on your machine learning team and diversity of your data. The more additional perspectives you get, the better chance you’ll have of avoiding snafus like this. It’s essentially impossible to understand everything that might go wrong when you’re training your models and for a lot of us, we simply don’t have the budget to hire teams big enough to feel like we’re covering all our bases. But we can go out of our way to solicit additional input and provide additional opportunities to people and perspectives that aren’t currently extant on our teams. We can gather data in new places and in new areas to make our solutions more universal. We can use labelers from across the world to make sure our datasets account for more nuance and additional outlooks.
In other words, by increasing opportunity and diversity, we behave ethically and create better models. Sounds like a win-win.
Continue open sourcing
One of the easiest ways we as a community can increase opportunity in AI is by continuing a trend that’s long been part of our work: open sourcing.
Because let’s be frank. Opportunity to work and shape AI isn’t universal now. It’s not even close. We’ve got a ways to go, in fact. But open source ML libraries and open datasets — think everything from CIFAR to the UC Irvine ML library to Imagenet — are something each of us can contribute to our community and increase opportunity in AI.


Being able to teach oneself machine learning tactics on small, well-curated datasets allows people who can’t afford university or can’t find work in the field the ability to train themselves. It affords them the opportunity to truly become part of the community, sharing code and novel approaches, learning from scientists with more experience, building their CV, and so much more.
We can all give more people more opportunities in AI by doing this. And we of course understand that not everyone can open source everything they work on, especially when it’s part of their day jobs. But publish what you can. Share what you know. The more people who understand AI and shape it, the better off we’ll all be.
More meaningful work for all
No matter what technology we’re talking about, there’s always worry about the attendant technological unemployment. From sewing machines to robotics in factories, society has frequently worried that the march of progress will leave some people behind and replace some jobs that kept families afloat. And it’s a good thing to worry about. Technology should make our lives better, after all.
Even the most optimistic AI prognosticators understand there will be disruption. But I want to start with a conversation I had on LinkedIn earlier this month around the release of a Microsoft product that creates HTML from hand-drawn images:

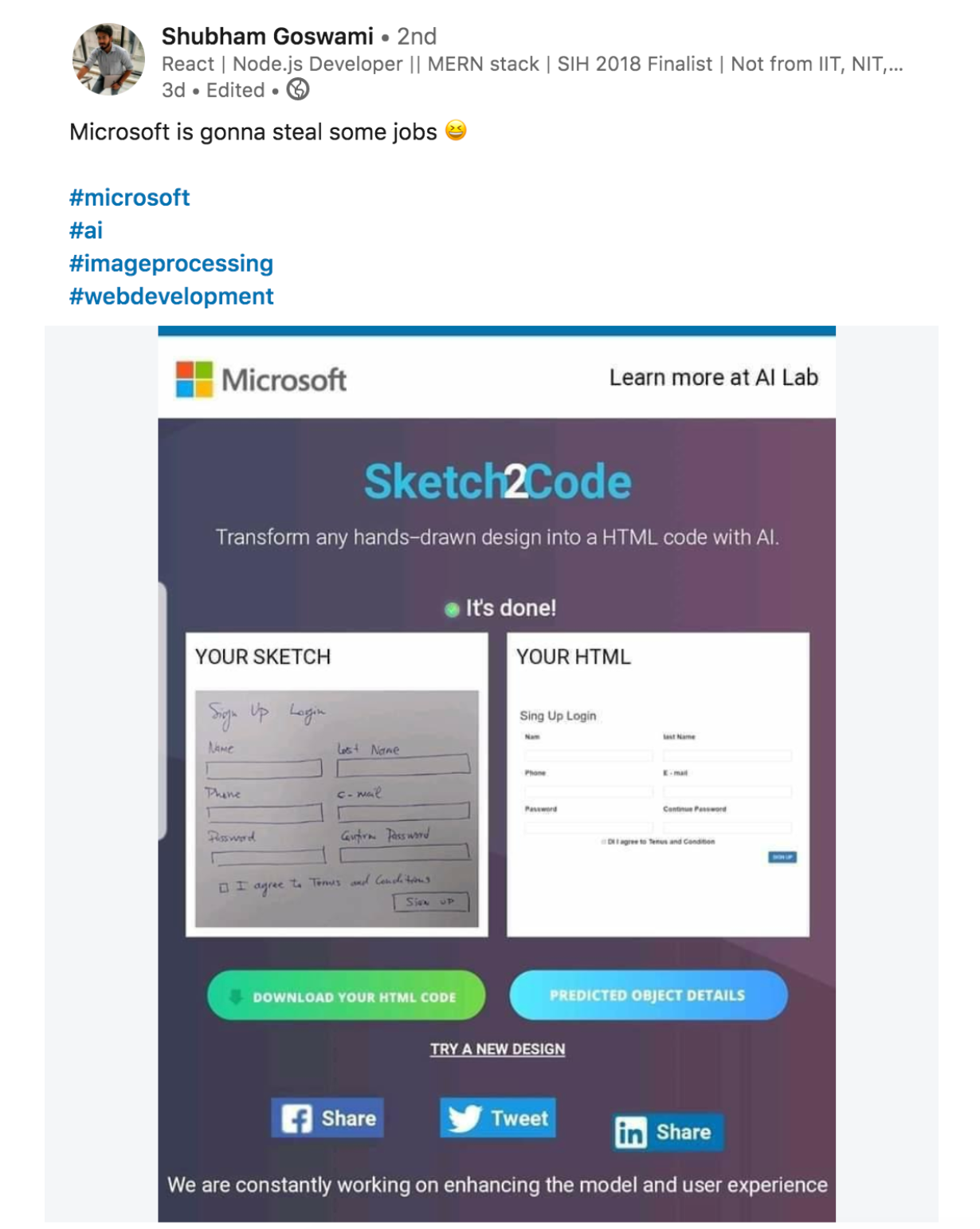

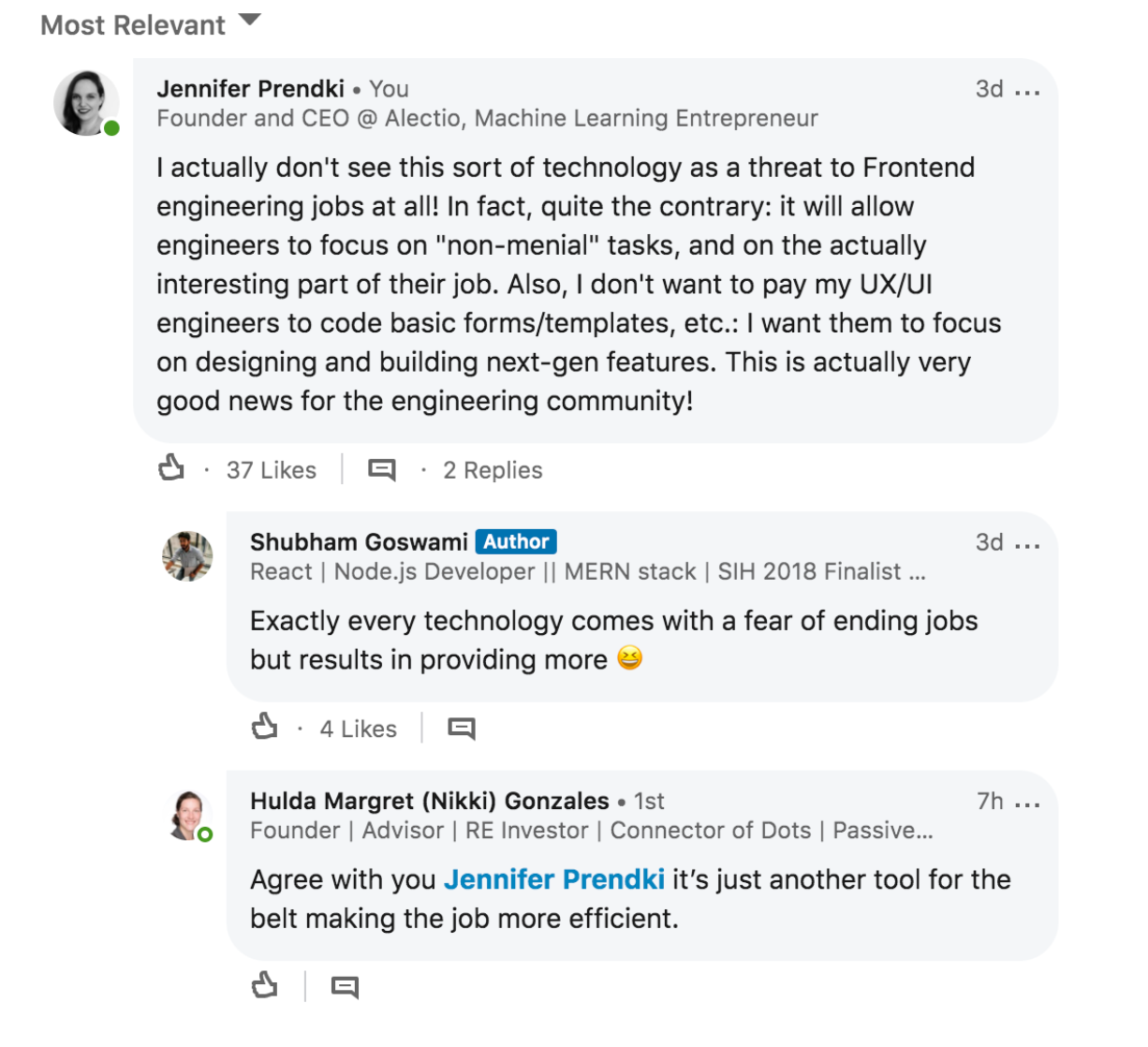
It’s my view that this is the sort of disruption we’ll see far more of in AI: not types where jobs are subsumed wholesale but ones where jobs are altered forever.
In other words, instead of a designer or an engineer losing their job, this product might save them valuable time by automating something easy and a little bit tedious. As medical image recognition improves, you’ll see radiologists outsourcing the obvious scans to machines and spending more time and energy on edge cases that machines can’t confidently predict. Customer success organizations can use AI to triage important issues before they balloon out of control. Satellite imagery can augment and transform everything from climate change research to business logistics to stock forecasting. And in none of these areas does the technology we’re talking about actually remove jobs. On the contrary: AI makes those jobs easier and makes work more efficient.
In other words, as AI helps us mitigate and replace the most redundant parts of our jobs, it will place creative and intellectual work at a premium. Responsible AI means that we deputize machines to take care of the easy stuff so humans can use their heads and their hearts to do work that machines never could.
In the end, we need to go beyond how we’re currently thinking about AI for good.
It’s not all about bias and fairness. It’s not just about democratizing cost or access. It’s not simply about making sure resources and education are available to people who need it. It’s not only about reducing our environmental footprint.
It’s about all of it. Because AI shouldn’t just be about streamlining business processes or making government work better. It should be about making our world better. It’s a technology that has the promise to do so but experts need to take the lead and help insure AI grows responsibly. We need it to help the people in need, not just the people on top.
Responsible AI is our common responsibility. And we’ll be doing our part to make sure that becomes a reality.
Read the previous posts:
- Part 1: How we got responsible AI all wrong
- Part 2: Impact, Bias and Sustainability in AI
- Part 3: Increasing accessibility to AI