



Great news: this is actually not true, even though the new technologies that can be used to put data prep on autopilot are still not completely mainstream. There are in fact many ways to leverage Machine Learning and new technologies in order to speed up, partially automate, and even increase labeling accuracy and hence, model performance.
1. Autolabeling
Autolabeling is a term that refers to the usage of a pre-trained Machine Learning model (such as YOLO, CDD or Faster-RCNN in the context of object detection, but the concept can obviously be applied to other use cases as well) to generate synthetic annotations for the training dataset to be used to train the user’s model. The pre-trained model basically replaces human annotators.
Autolabeling is clearly very appealing to those working with very large datasets and/or who are looking to keep their budgets and timelines under control. The approach also offers the unique advantage to compute a confidence score for each prediction, which provides a measurement of the trustworthiness of the annotation and can help decide whether one wants to have a human annotator validate or redo the annotation; the latter is what people call Human-in-the-Loop data labeling.
One of the limitations of autolabeling is that there is a cold-start issue: unless you are working with a relatively common use case, it might be hard to find a reliable pre-trained model that you can use. However, with the help of Transfer Learning, it is possible to extrapolate off-the-shelf models into something more custom by training on smaller datasets.
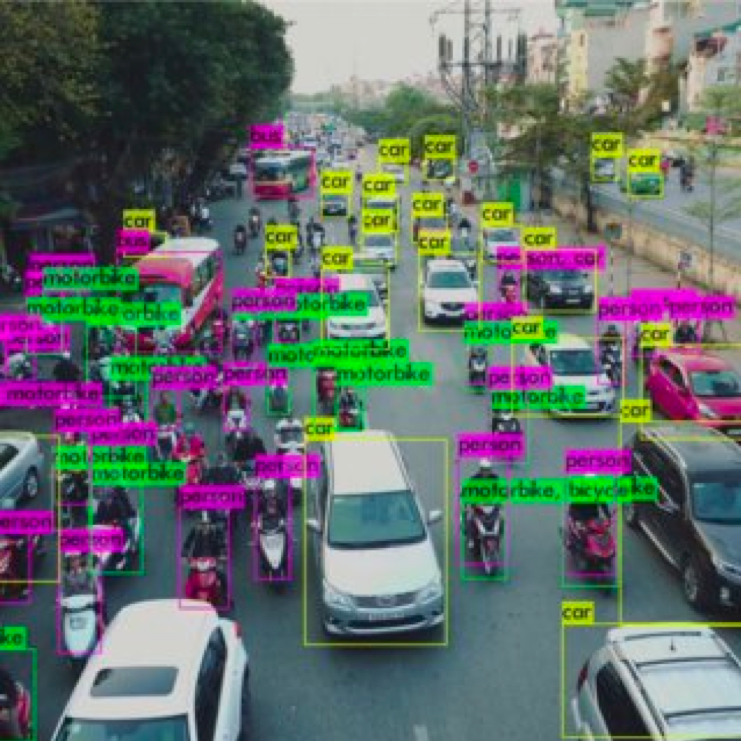

2. Better Labeling Tools
If the data is to be annotated manually, the annotation tool that is put in the hands of a human annotator can make a dramatic difference in the reliability of the results – and of course, on how hard or easy the work will be.
Some advanced labeling tools use autolabeling to “pre-generate” annotations that the human annotator can choose to keep or modify: as seen before, this is the quintessential Human-in-the-Loop labeling approach, which has been growing in popularity in recent years. In fact, the most advanced of those tools leverage the modifications made by the annotator to improve and fine-tune the autolabeling algorithm itself.
But Machine Learning is not the only technology that can supercharge the latest annotation tools: UX research also makes it easier for human annotators to generate and modify labels easily, to assign specific tasks to other peers for a second opinion, or to leave comments for the customer directly when there is a need to discuss the contentious record. Note also that many labeling tools saw the light of day before cloud technologies became completely mainstream, so the ability to collaborate on the same data with other people was not naturally embedded on their platform, and this also is an important shift in the new generation of labeling tools.
3. Recommendation Systems and Marketplaces for Data Labeling
Today, if you plan to hire a labeling company to annotate your data, you’ll have to review a few of them before settling for one, based on the understanding that you have of their ability to deliver on the use case you are currently working on. Sounds a lot like the old-fashioned way to shop around, doesn’t it? This is exactly why the concept of the marketplace gained so much popularity when online shopping became mainstream. There is no reason why shopping around for a labeling partner should be any different: you should be able to compare and get recommendations for partners based on actual data as opposed to just going with your intuition. Luckily, recommender systems can be built to provide that functionality; in fact, that’s precisely what the Alectio Labeling Marketplace can do for you.
Then, once you sign up for their services, you will be stuck in a long term engagement, just like with a cell phone provider. If they don’t deliver or are not meeting your expectations for a current or even future project, there is little you can do until your contract expires. This makes reliable reviews from other customers even more important, and one could imagine how secure review management systems (potentially built on top of Blockchain) could completely change the game here.
4. Infrastructure for Data Labeling and Data Prep
Though it is hard to believe, even in 2023, when sharing data and labeling with a third-party labeling partner, a data scientist would have to rely on Google Drives, s3 buckets and old-fashioned email communications. Labeling companies relying on API communication are still few and far between. This implies that as a customer of such a company, you are not able to easily track progress or provide real-time feedback. It also means that sending more data on the fly is practically out-of-the-question.
The fact that labeling partners haven’t modernized their infrastructure is a huge dichotomy with the MLOps industry which has been built on top of advanced data orchestration workflows that can manage, among other things, real-time model training and autoscaling. Because of this, Data Preparation is still the bottleneck to many ML projects. When you think about it, what is the point of automating the retraining of a Machine Learning model when you will have to manually manage the new data that it will be retrained on? Luckily, more and more workflow orchestration platforms (such as Flyte) have been built in such a way that it can manage real-time data preparation and scale properly.
5. Active Learning and Advanced Data Curation Algorithms
Until today, the general trend is still for data scientists to rely on Big Data. If your model isn’t performing well, you have been taught that you should increase the size of your dataset, which makes sense at first since this is the default way to improve generalization. This trend has in fact given rise to more scalable data management solutions and to Synthetic Data Generation technology. However, working with large datasets involves substantially more resources (in terms of talent, time and money), and as the global amount of data keeps growing steeply, even the top cloud providers are starting to show signs of weakness (Azure even ran out of computational resources for their own customers!).
This is where Data Curation – the process of removing useless and harmful records from a training dataset – can help. Done properly, Active Learning or the more advanced variations of Data Curation will lead to training models of similar (if not better) performance with a fraction of the data, and hence, with less money spent on labeling, storage or computational resources.
6. Weak Supervision
You might not be familiar with the concept of Weak Supervision, but might have heard of the “Snorkel algorithm”. The idea behind it is as simple as it is game-changing: it is based on building labeling functions (which can be rules-based functions, embeddings or actual ML algorithms) which can be used to quickly generate annotations. In its most simple form, a labeling function would be a list of rules provided by an annotator, but it could also be a more complex function learned on a dataset. Those labeling functions are then consolidated and aggregated, for example in the form of a voting algorithm. Ask 10 medical experts how they would decide the prognosis of a patient generally speaking, then apply their respective thinking to build a consensus on each patient (record). This is just as if you had asked the opinion of 10 doctors on the case of a given patient, except that you can now apply the same system for as many patients as you’d like!
While powerful, Weak Supervision can still be tricky to implement as any bias in a labeling function would lead to scaled-up biases on entire datasets; it also does not address challenges associated with computational resources and might in fact increase the amount of money spent on compute.
7. Smarter Labeling Instructions
Creating air-tight labeling guidelines is extremely difficult, as it is practically impossible for a human not to miss a specific corner case. However, one way to address this is to leverage an approach like weak supervision to generate general rules and guidelines addressed to a human group of annotators. This is like a human-in-the-loop version of weak supervision, which allows to catch any potential overgeneralization from the weak supervision process itself.
At Alectio, we have also developed a quiz-based algorithm that allows to generate annotations that follow a set of best practices (such as enforcing a minimum number of examples and counterexamples based on the predicted likelihood that a human would make a mistake under the circumstances) and computes a score that measures the reliability of the instructions. That said, many news technologies (including Conversational AIs like ChatGPT) will most likely change the way instructions are generated long before the process of Data Preparation can be fully automated.
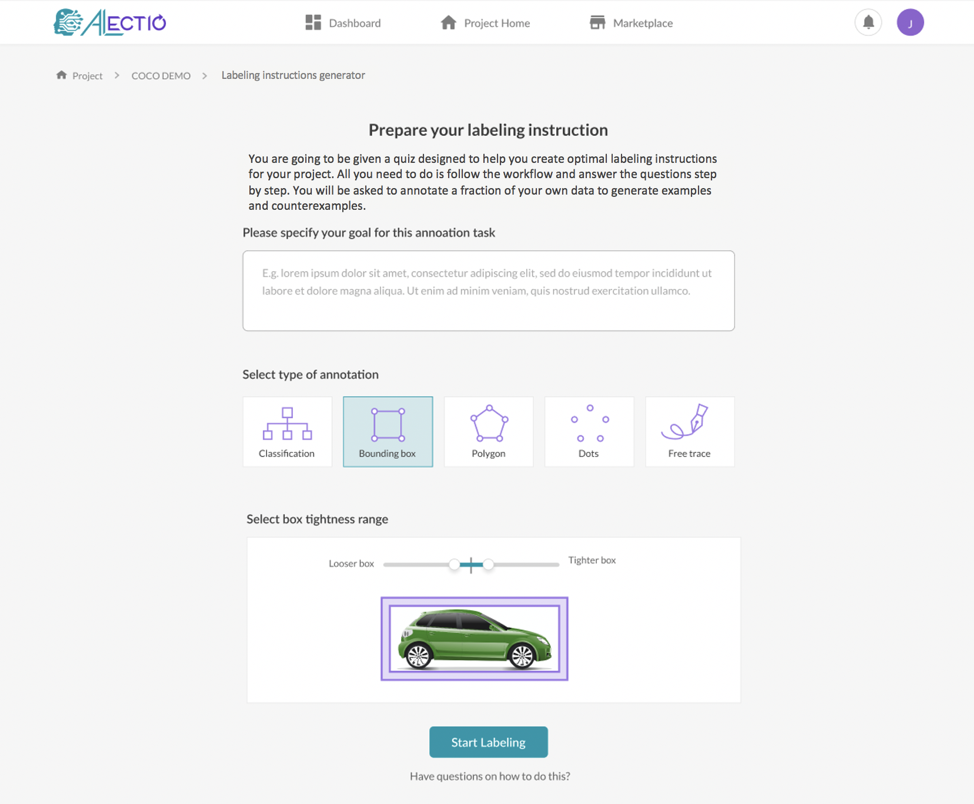

8. Automated and Real-Time Label Auditing
Tuning a dataset is one problem, catching problems when the generated labels or data has been generated incorrectly is another. It is equally important to develop systems to automate Data Preparation as it is to do quality control after the fact. For example, most Active Learning approaches are very sensitive to bad labels, which is why validating labels as they get generated would be extremely valuable to get better models.
Anomaly detection techniques applied to labels might not seem like a very high-tech approach, but it is actually surprisingly powerful to reduce biases in Active Learning and an easy way to find weaknesses in labeling instructions. Auditing annotations can also be done with more advanced ML and statistics-based techniques, such as using time-series analysis to look for abnormal or sudden changes in model parameters and measure how likely or not a specific record is to be mis-annotated.
9. Synthetic Data Generation and Guided Synthetic Data Generation
Synthetic data generation is poised to make a huge impact in whichever industry where collecting and/or annotating data is expensive, time-consuming or fastidious. And with the fast growth of the Generative AI space, the possibilities seem endless. Imagine diagnosing a weakness in your model – for example, finding out that a specific class happens to have a very low accuracy – and being able to address that issue immediately by generating the right data to resolve the problem.
This is exactly what guided synthetic data generation is all about: it marries data explainability techniques and statistical methods to learn how the training data impacts learning, going as far as identifying which parameters are impacted by specific records. After decades of treating Deep Learning models as black boxes, we are finally starting to be able to uncover how data is being encoded into information and decide strategically what data to generate instead of doing it randomly.
If you are among the many ML experts who until today have perceived Data Preparation as a low-tech process, then you hopefully have changed your mind by now. Data Preparation is in need of the attention of the best ML researchers before it can reach the same level of maturity as model development or MLOps. However, it is perfectly conceivable that just a few short years from now, preparing and optimizing a dataset will be as simple as downloading a pre-trained model or even using a prompt. Follow us today on our mission to make data prep a high-tech discipline leveraging the most advanced data engineering and Machine Learning techniques on the market.