
The past few years have been incredibly exciting for the Machine Learning research community: from Generative Adversarial Networks (GANs) to Learning-to-Learn, it seems that a new training paradigm or a new model architecture is seeing the light of day every month. While a portion of those concepts receive lots of press, some others go unnoticed by all but the few experts, or groups who pioneered them. Of those, perhaps the most underrated of all, is Machine Teaching.
At Alectio, we are no strangers to Machine Teaching, because of its strong relationship with Data-Centric AI, which we have covered in detail elsewhere. Before we can explain why Machine Teaching is of critical importance to Data-Centric AI, let’s start by deep-diving into what Machine Teaching actually is, and how it relates to Machine Learning.
If you are visiting this blog, you likely already are familiar with the concept of Machine Learning (ML). You also probably know that ML is the practice of getting a machine to act as a human without explicitly programming it to do so. Machine Learning essentially relies on (passively) feeding training data into a model, and expecting the model to extract knowledge from it without the explicit intervention of a human. With ML, the computer is left to its own devices and is expected to “figure things out” on its own, to self-learn. When they do ML, data scientists are in fact like bad teachers who drop large, uncurated piles of books on the desk of their students, promptly leave for lunch, then come back expecting those students to have become experts in the topic. By using this brute-force approach, any school teacher would immediately earn the reputation of being a “bad teacher”. So it is shocking that the majority of the data science community has turned so complacent as to accept this approach as the right way of tackling AI.
Luckily, some ML thought-leaders realized the inadequacy of this method, and decided to challenge the status quo. The first group proposed that in order to improve the pace of learning, the teachers should focus on either improving the book selection, or the quality of their content: this is the Data-Centric approach. A second group advocated to abandon the old-fashioned passive way and to start analyzing the way the students learned in order to adapt the content they should be exposed to and/or the way, context or pace at which this content should be presented to them: that is, in a nutshell, the Machine Teaching approach.
Formal Definitions
Now that the context has been set, let’s jump into the more technical jargon by starting with proper definitions:
Data-Centric AI is an approach to AI and ML that consists of improving a model’s performance through modifications made to the training data, or to its labels.
With Data-Centric AI, extra attention is put on ensuring a reliable representation of the information that the model is meant to learn. However, contrary to common belief, there is no requirement that the data is improved incrementally, and the improvements are not necessarily derived from the model’s feedback. That being said – both those conditions are met in the large majority of cases. An example would be Weak Supervision: a technique that leverages weak classifiers, and seeks to statistically encode the knowledge of multiple subject-matter experts on a specific topic to generalize the generation of data labels at scale; that technically still qualifies as a part of the Data-Centric family of algorithms, even though it does not explicitly take model feedback as an input.
Machine Teaching, on the other hand, is the concept of influencing (usually to improve) the learning process of a model dynamically or taking educated actions to alter the course of training.
It typically involves some form of reverse-engineering of causality effects observed during learning that allows the teacher to gain knowledge on the student and leverage that knowledge to boost the learning curve. Such interventions are conventionally made on the data rather than the model, because acting on the data is more intuitive to humans than acting on the mechanics of a model, especially when that model is a black box. However, Machine Teaching is a young field, and is to be expected that, at some point in the future, researchers will eventually seek to actively tune the algorithms themselves. This means that methods that seek to speed up learning by dynamically acting on the model’s hyperparameters or architecture (such as the Learning-to-Optimize algorithm, a novel yet powerful Meta Learning technique) still qualify as Machine Teaching, since they’re an improvement on a brute-force, passive Machine Learning approach. It also means that, paradoxically, data poisoning attacks are also to be considered as Machine Teaching since a teacher (the data scientist) is voluntarily making (malicious) changes to the data in order to interfere with the “natural” course of action during the training process.
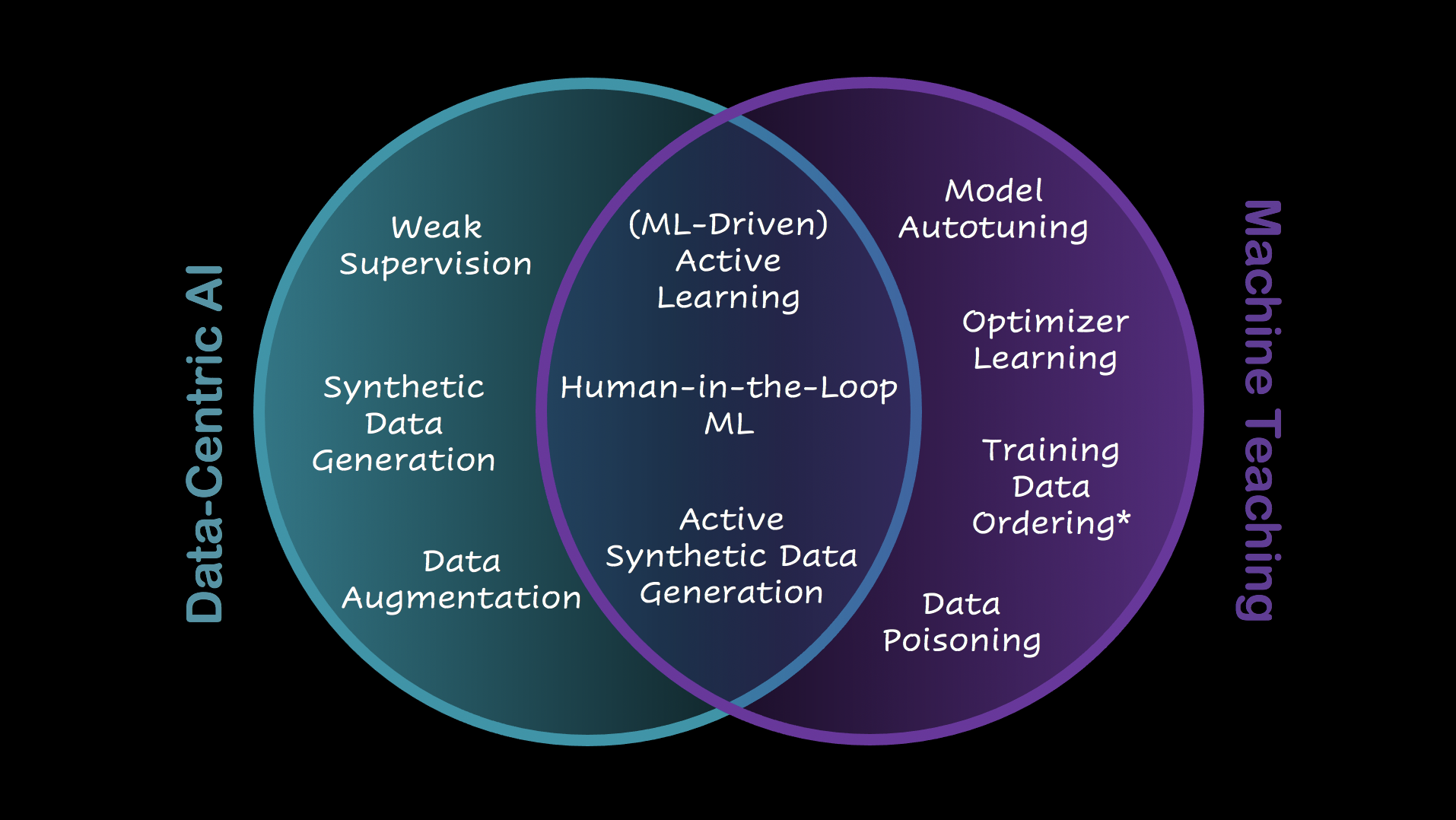
Who / What is Teaching?
Whenever the concept of teaching is involved, it is natural to wonder who (or what) is the teacher. In its original form, Machine Teaching is when a human agent “teaches” (or intervenes in the learning of) an ML model: Human-in-the-Loop ML would fall into that category, as would regular Active Learning where the querying strategy is a rule set by a human. However, the most promising research area, which ML experts have barely scratched the surface of, is the study and development of automated systems that can assist in teaching another machine, either by dynamically tuning the data (which is what ML-driven Active Learning is all about), or by dynamically tuning the model (such as an Autotuning algorithm or some categories of Learning-to-Learn algorithms).
Better Books Doesn’t Mean Better Teaching

While Machine Teaching differs from Data-Centric AI, there is a clear benefit from combining both paradigms to get a more powerful process that can convert information into knowledge. Neither Machine Teaching nor Data-Centric AI insist on the absolute need to rely on the incremental or continuous feedback of the model, even though Machine Teaching strongly suggests it. Having dynamic changes made to the data to optimize the information ingested during the training process is by far the most researched in that space. That’s because the most natural way to teach is to simultaneously give personalized attention to the student, and the correct personalized content for the student to learn from.
With all that said, Machine Teaching is still a nascent space which deserves much more attention from experts. Actively teaching machines would be a much needed step forward to reach better cost efficiency in AI, and a better understanding of how machines learn which is critical to the advancement of explainable AI. Think for example that today, we’re capable of generating photorealistic pictures from a simple caption. And yet, even though the entire ML community acknowledges that the order in which training data is injected during the training process significantly influences the final performance of a model, no framework whatsoever has been proposed to make informed decisions on how to optimize that order.
The aforementioned combination of Data-Centric AI and Machine Teaching is at the center of most of the research led by the Alectio ML team. From the development of novel ML-driven Active Learning algorithms (which aim to select the most beneficial data by continuously analyzing the training process of the model) to Active Synthetic Data Generation (which programmatically informs and guides a synthetic data generation process based on real-time model feedback), our team is trying to revolutionize the way models learn from data today.
We hope you enjoyed this article and that some readers will use it as inspiration to advance Machine Teaching research. If you would like to learn more, feel free to follow Alectio on LinkedIn, Twitter, or to contact us for a deep dive into how we apply these techniques into our solutions that power Fortune 500 companies and government agencies around the world.



0 Comments