Deep Dive on Active Learning
What is Active Learning?
Active Learning isn’t anything new, and it’s not very complicated either, once you get the idea.
It was originally developed for the purpose of reducing labeling costs, but it actually offers countless other benefits which the Alectio Platform will help you gain full advantage of.
Its workflow is very straightforward, and is based on an iterative approach. Each cycle is called a loop.
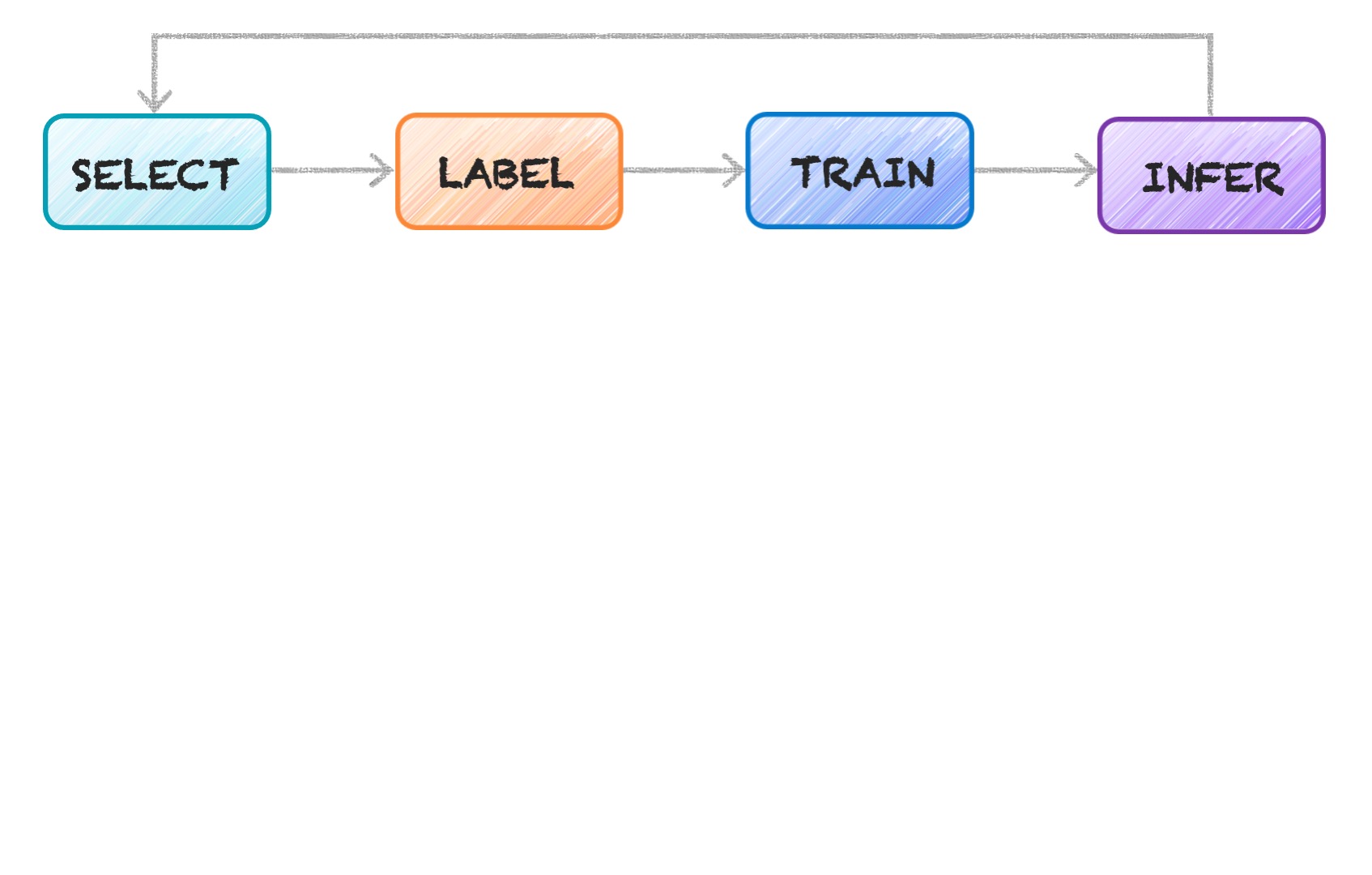
The SELECT step consists in choosing which records will be added to the training dataset before proceeding further.
That step could be taken care of manually by subject-matter experts.
In most circumstances though, the sampling method is an arbitrary, pre-established and static rule called a Querying Strategy. Querying Strategies are usually derived from the inference metadata generated at the previous loop. Popular querying strategies include least-confidence sampling, but there are actually hundreds of them, and researchers develop new ones continuously.
At Alectio, we believe it's time to replace those arbitrary rules by ML algorithms trained on training and inference metadata collected from all past loops.
Before the model can be retrained with the selected data, we need to get it labeled. We’re talking about micro labeling tasks, as the amount of selected data is usually relatively small (in the hundreds), but we need the job done in near-real-time to accommodate an Active Learning process.
For some use cases, the LABEL step can be done by an automated process, like a pre-trained Machine Learning model (this is called autolabeling), or an approach like Weak Supervision. However, since in most situations, there are no pre-trained models to be used (and using a Machine Learning model would lead to a chicken-and-egg problem), the Alectio team solved the real-time labeling issue by creating a Labeling Marketplace full of partners supporting real-time labeling, as well as a sophisticated Labeling Resource Allocation system looking for annotators immediately available to label data.
Once the selected data has been annotated, and the annotations have been validated, it’s time to re-TRAIN. The training process is fully orchestrated by the SDK which signals which records to train (or re-train) with, without you needing to do anything on your end.
The Alectio Platform has been designed so that your training process is fully hosted on your system, so that you keep full ownership of your model and don’t need to expose your data. You are free to use any framework or library you’d like, and don’t need to migrate to a new system you do not know.
Don’t have a model? That’s okay too! You can pick a model from the Alectio model library and use it to curate your data.
Just like training, the INFER step is triggered on your system so that you do not need to export your model and IP.
The model that just finished training is now used to generate predictions on the remaining (unused) records in your data pool. Those predictions and all sorts of metadata associated to the training and inference steps (such as the computed outputs of each layer) are captured by the SDK and sent back to the Alectio Selection Engine, where they are used to generate a recommendation regarding the next sample of data to use in the next loop.
You are fully in control of which metadata get shared with Alectio and can decide how invasive you allow the process to be. Because the metadata isn’t enough to reverse engineer the data or model, no adversarial attack can threaten your system.

Active Learning can be broken down into two main categories:
- Streaming Active Learning, where the algorithm decides whether or not to keep a record one-by-one. This technique tends to be more compute-efficient as it is not necessary to assess the entire dataset before selecting a record, but it fails to control the quantity of data that gets selected. An example of streaming approach would be to apply a confidence-level threshold to filter data for the next loop.
- Pooling Active Learning, where the algorithm scans through the entire remaining pool of unselected data to select the most interesting records. While more computationally expensive, this approach offers the advantage of being able to tune the quantity of data (and hence, the budget), better.
What is a Querying Strategy?
Active Learning consists in dynamically choosing some records from raw, unannotated data, and getting those records annotated so that they can be used for training. The workflow is essentially about moving records from what we often refer to as the unselected data on this website, to a selected data pool. The question of how this selection is made is what querying strategies are all about.
A querying strategy (sometimes also called a selective sampling method) is simply a function that selects a sample of data to be annotated and used for training in the next loop. How this function gets chosen, is naturally the bigger question.
Most data scientists familiar with Active Learning assume that there are only a few querying strategies to pick from, just like there is only a finite number of different ML algorithms, but this is actually incorrect as a querying strategy can literally be any sampling function.
In general, people who use Active Learning pre-determine a static, arbitrary querying strategy set once and for all before the beginning of the process. Because Active Learning isn’t mainstream in the industry, very few people have developed the necessary expertise to choose those strategies wisely, leading to poor performance which leads many to give up. Besides, there is actually no reason why the same query strategy should be used through the entire process. For example, some querying strategies provide a really high compression but are computationally-greedy, which might make them suitable candidates only for the earliest loops when the amount of selected data is still low.
At Alectio, we wanted to address all misconceptions about Active Learning by completely rethinking what a querying strategy should be and taking a Machine Learning approach to building a querying strategy.
Why is Active Learning not as easy as it seems?
- Multi-Generation Active Learning
When selecting data for a given loop,vanilla querying strategies rely on the outcome of the previous loop only. That said, the state of the model and metadata generated over the entire lifetime of the process contains precious information that has been disregarded by ML researchers so far. One of our breakthroughs was to treat all metadata as time-series rather than singular values. - ML-Driven Active Learning
- Meta Active Learning
- Learning-to-Active-Learn
- Compute-Saving Active Learning
Even with the perfect querying strategy, Active Learning presents a major disadvantage: it is extremely compute-greedy. That’s because the model is re-trained from scratch with the data selected so far at each loop.