
AI research is accelerating, and with it, the development of new MLOps and DataOps tools. Labeling tools have been no exception: both open source tools and dedicated companies have been popping up at an unprecedented rate over the past few months. It looks nowadays, ML teams have hundreds of options available – which is absolutely true -, but also that all options are more or less equivalent to the competition. After all, an annotation tool is an annotation tool: how can one be fundamentally superior to the other to the point of warranting thousands of additional dollars in licensing?
The reality, though, is that picking the right tool can be critical to the success of your Machine Learning project, and it is nowhere as straightforward as you might imagine. In fact, it depends a lot on how you plan to use the data, and not just the use case, but also the weaknesses of the model that you plan to train with it. And it might be even trickier to source the right tool for the job if you don’t plan to annotate yourself.
But do not worry, we wrote this article just so that you could navigate the space better, and learn what you should look at before choosing (or purchasing) a new annotation tool. And as you will see, it is not all about the number of features or its sex-appeal.
How good (really) is the UI?
Saying that you need a good UI might feel like a self-evident statement, but it is far more complicated for a UI designer to build an easy-to-use annotation tool. Keep in mind that annotators spend a lot of time on those tools, and the most insignificant issues which you might not notice when labeling just a few (or a few tens) of records might turn out to be a major source of user fatigue when used extensively.
A carefully designed and tested tool will make a difference in terms of data quality and cost in the long run. However, this is easier said than done; here are just a couple of things that you will want to look into, both if you have been tasked with building a tool, or of choosing one.
- Modifying
When annotating data, you won’t only have to generate annotations: you will also need to adjust and modify them continuously. This is especially true now that the Human-in-the-Loop paradigm is becoming more mainstream. You might have to review your own output, somebody else’s, or even go over the predictions of a Machine Learning model and fix its biases.
But making changes, say, to existing bounding boxes, can be relatively challenging, especially when the density of information is high and many bounding boxes overlap. In that case, your tool needs to provide the functionality of hiding boxes that you are not working on, of manipulating layers (bringing the ones from the back in the front so that you can resize them). Small bounding boxes might be challenging too, as seeing and grabbing their edges or handles might require really good ideas and great dexterity (we will discuss the importance of zooming in the next paragraph).
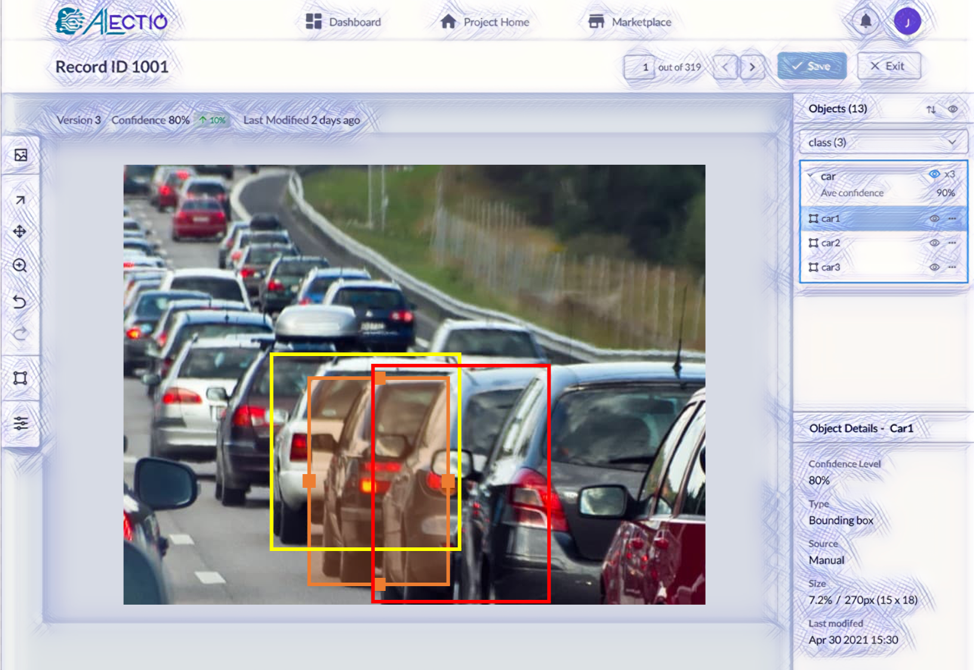
In this case, modifying the orange bounding box can be challenging if the handles of the box are behind the two others.
- Zooming
Annotating data requires careful attention to details. In case of image data, this means potentially annotating tiny elements that are barely visible to the human eye. The ability to quickly and easily zoom in and out can both reduce eye strain and improve the quality of the results. That said, few tools provide additional functionalities beyond the standard zooming capability. While some do not even provide a pinch-to-zoom feature and require clicking on buttons to zoom in and out, practically none offers magnification capabilities.
- Positioning of the UI elements
Not unlike the work that designers do on tools like Adobe Photoshop or After Effects, annotating data is a lot about mastering the usage of a mouse, with both speed and precision. You have to navigate from one record to the next, then back when you realize you made a mistake, then might need to zoom in and out quickly, delete a bounding box you marked, etc. – all of this again, and again, for hours in a row. Imagine the waste of time if the “create new box” button is on the opposite side of the screen compared to the “delete” box button, or if the key button are far away from the picture you need to draw shapes on: this would be the same as placing your artist palette on a table several feet away from your easel, and this explains why each button has to be placed VERY strategically. This is also why you have to try an annotation tool for sufficient periods of time before making an informed decision about how good it truly is.
- Colors
Colors are more than a matter of aesthetics when it comes to labeling tools, and in particular, to object detection annotation tools. Have a look at the picture below and you will immediately understand what I mean by that: ensuring a high contrast between a bounding box and the target object as well as its background can be very challenging. Good annotation tools compute average colors on the image to guarantee that the contrast is high in order to avoid eye strain for the annotator, or at least leave you the option to pick colors yourself.
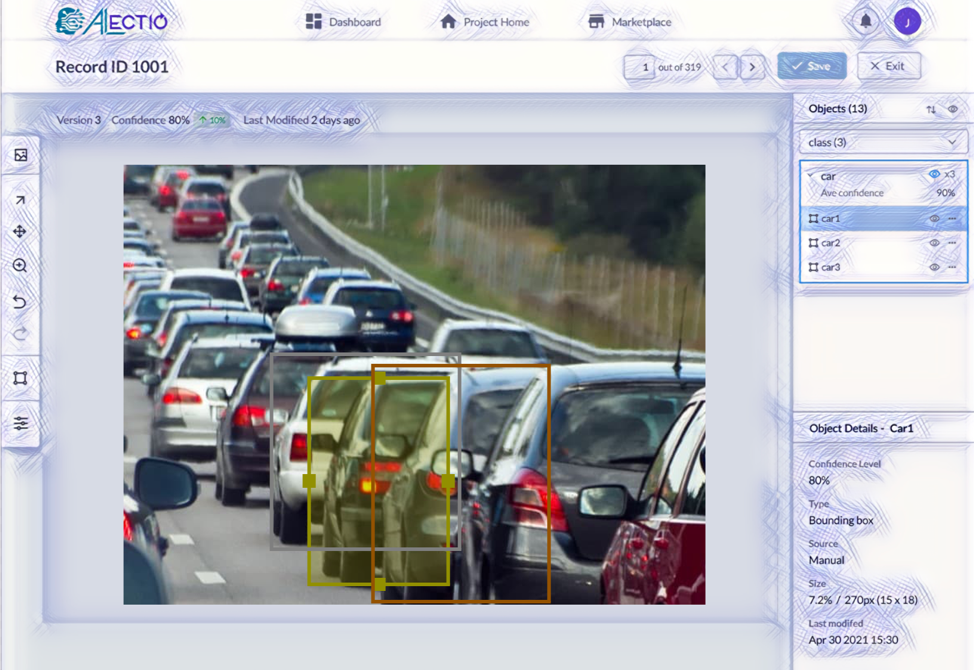
This is obviously a poor color choice for the bounding boxes, given the color scheme of the image.
- Shortcuts
We’ve seen earlier that the position of different buttons on the UI could make or break the tool, but the existence of easy to use shortcuts can sometimes make an average tool into a good one, assuming that the annotators can learn the trick fast enough and take advantage of them.
Is the UI designed to reduce biases?
A first thing to look at is whether annotators can skip records. Why would you want annotators to be able to skip records, you’ll ask? Because sometimes, there is no applicable answer, or because the annotator just doesn’t know or wishes to decline to provide an answer rather than providing a bad one. Many annotation interfaces just won’t let the user move forward to the next record unless she provides an answer, so she eventually has no choice but to select an answer randomly (or worse, select the one at the top of the list) in order to move on. This can lead to major biases in the labels which can lead to detrimental consequences on the subsequent model trained with the data.
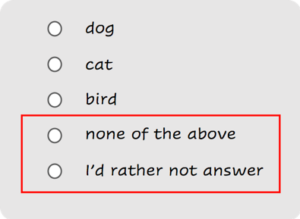
A good Data Labeling Took should always include options for the annotator to skip the record.
Another important consideration is the order in which the options are displayed. Tired annotators are more likely to scan only the first couple of options, so if the top two are always ‘cat’ and ‘dog’, the other options will be picked less frequently even if they’re the “right” answer. Things get even more complicated when the task is to be annotated a data for a classification problem with hundreds of classes: the annotator is then unlikely to be able to view all options; in fact, a radio button interface might not be a good choice anymore, and it might be better to have a dropdown interface. The ideal data labelabeling tool would in fact offer a different interface depending on the number of classes.

Randomization of the options as well as different interfaces depending on the case is crucial to avoid biases.
Can you customize the format of the output?
Unless the data annotation tool is directly connected to your model training pipeline, someone will eventually have to extract and save the annotations so that they can be used in another system. At that stage, that person will have to decide on what format to download those labels into. This involves answering questions such as:
- Whether it be a .csv or an .xml file?
- Whether the bounding boxes should be referred to the coordinates of their top left and bottom right corners, or their centers and width and length?
- Is the pixel or the ratio of the image the right unit of size?
- Should annotations for each record be saved individually?
Having to transform them after the fact will make things a lot trickier and time-consuming than they should be. In the worst case scenario, they will be just plain wrong and no one might even notice it before the model is trained. That’s why these are important matters to be resolved before the results are saved.
Can annotators leave notes and comments?
Annotating data might seem like an individual job, but it’s really a team effort. When the dataset is large, it goes without saying that having several (and even many) people involved is critical. However, having multiple annotators involved in even smaller tasks is key to reducing biases, and frankly, it is often helpful to discuss corner cases with other people when labeling data. Shortly put, collaboration both with other annotators and within the team that requested the annotations can really take the project to the next level.
One way to make an annotation tool more collaborative is to provide ways for annotators and requesters to communicate with each other. Usually, when one sends data to annotations,they will share with them a static document called “labeling guidelines” which is designed to communicate with the annotators the expectations for the task.
Can the tool manage multiple judgments?
Few people apart from those who have actually used the services of a third-party labeling provider know that in practice, each record is annotated more than once, by different people. This tactic is designed to reduce the probability of a given record being mis-annotated and guarantee diversity of representation in subjective labeling tasks.
But how does this have anything to do with the quality of a data labelabeling tool? After all, each annotator can work on their own instance of the tool and get their respective results merged afterwards. Well, that’s precisely where things get tricky. First, the tool needs to provide the ability to expert the labels in formats that are easily combined by those of another person. It might seem like much, but it actually requires:
- A way to make sure that record ids match on all files to be merged, i.e., that the first record on each file corresponds to the same source.
- A way to easily combine each matching record into one
But you will want your ideal labeling tool to do more for you. In the ideal scenario, you should not have to merge the annotations by hand, as this is very error prone and fastidious. A really good annotation tool will give you the options to load the results of all annotators and visualize them layered on top of the original record. It will also provide support to let you choose the right aggregation function, as aggregating without viewing the results makes it likely that outliers will not be properly removed, and you will end up getting very little benefit out of getting multiple annotators work on the same records.
Can your data annotation tool manage automatic labeling?
Automatic data labeling is the use of a pre-trained ML model capable of generating synthetic labels to reduce the need for human intervention in the labeling process. Autolabeling can be powerful in the case where such a model can be leveraged, which is typically when the use case is not niche or overly specialized or subjective. The ability to bring-your-own automatic labeling model or even better, a preexisting autolabeling functionality already embedded in the product, make the implementation of a Human-in-the-Loop labeling strategy a lot more simple. The best autolabeling tools also provide ways to measure the confidence level of each prediction, an information that can be used to decide which records need a human second-opinion.
Can you easily implement workflows?
Workflows are rarely discussed in the context of Data Labeling, but they are incredibly powerful to keep costs under control and speed up any annotation process.
So what is an annotation workflow, and how do you set one up? This is the sort of concept that is more easily explained through an example than in theory, so let’s pick the example of license plate recognition. To annotate data to transcribe the numbers on a license plate, you will actually need annotators to perform two consecutive tasks:
- A bounding box task, to localize and mark any license plate
- A OCR task, to transcribe the numbers from the license plate into digits
Now, let’s assume that there are license plates on only 20% of the images, and that the per-record cost of a bounding box task is $0.25 and that it is $0.3 for the OCR task. Asking the same annotator would theoretically cost $0.55 per record. However, by splitting the whole task into two separate tasks would cost $0.25 + 0.2 x ($0.3) = $0.31 per record. This approach, of course, would require a pipeline that feeds the output of one task as an input to the next, conditioned on the value of the annotations for each record.
Workflows can be even more powerful in the context of automatic data labeling (aka, autolabeling) and Human-in-the-Loop labeling. You might want, for example, to use a pre-trained model to generate synthetic annotations, and have human annotators only review those generated with a confidence score under a threshold that you determine. And sadly, those functionalities are still not mainstream at all and are surprisingly difficult to find on the market, even in 2023.
Two of the most typical workflows used in the context of Human-in-the-Loop labeling:


New labeling tools are popping up like mushrooms on the market, and while most of them provide a lot of the same standard features, few really do extensive UX research to truly understand the user and accommodate their needs. Besides, even though automatic data labeling is becoming more and more common, few annotation tools provide any functionality to simplify the adoption of the technique. No labeling tool is ideal, and users (who are expected to spend many hours a day working on them) should not settle for something less than ideal. If you cannot find the right tool, give feedback to the makers so that they understand how to get better. The concept of annotation is too error-prone and too important to Machine Learning to satisfy ourselves with old fashioned, poorly researched tools designed by people who have never annotated a single record. We are responsible for making this industry better and taking it to the next level with DataPrepOps.



0 Comments