
Around the time when Data-Centric AI was gaining traction among experts, the Alectio team introduced DataPrepOps at TWIMLCon 2021; this was the first mention of the term. Most people did not perceive the two concepts as being related, but they are actually deeply interconnected: at a high-level, DataPrepOps is the operational side of Data-Centric AI.
What’s Data-Centric AI, and how does DataPrepOps relate to it?
Unless you are a complete beginner in Machine Learning, you would know this much: feedback loops are essential to ML and MLOps pipelines. Building a Machine Learning model revolves around cycles involving training, validation and tuning a system until one is satisfied with the results.
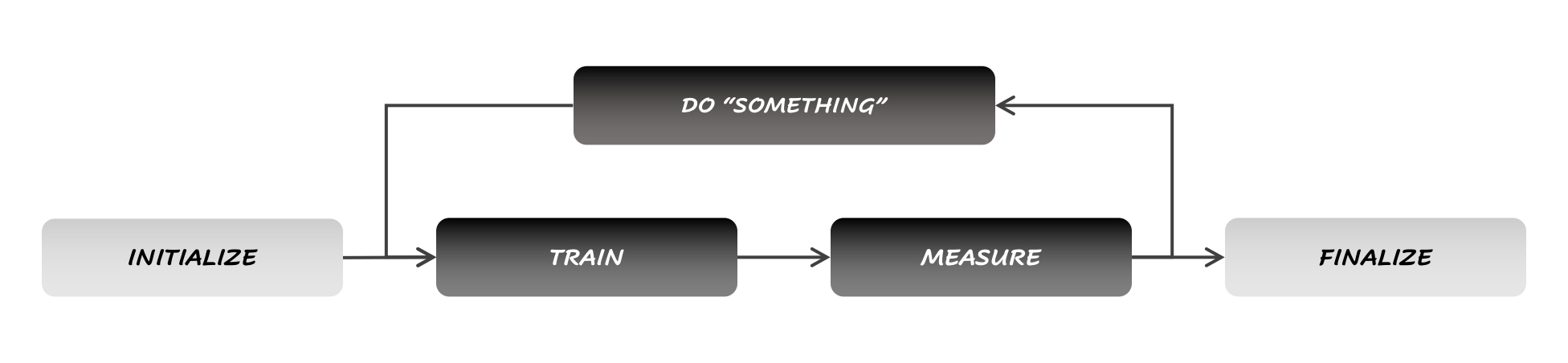
Figure 1: General workflow for most Machine Learning processes
Until recently, though, the tuning would be applied to the model itself; the training dataset, however, would be considered immutable and static, and no changes would be applied to it. So much so, in fact, that touching the dataset would systematically make the data scientist feel like he/she is inducing biases in the training process. Modifying the model rather than the data is what Model-Centric AI is all about.
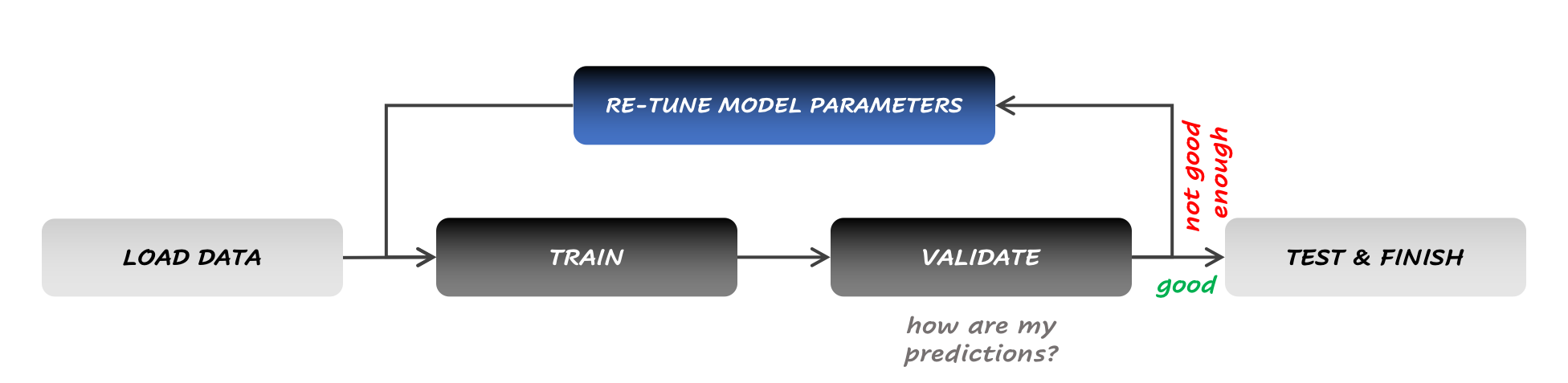
Figure 2: The workflow for Data-Centric AI
Yet as the practice of Machine Learning started evolving, it became apparent that tuning the dataset was paying off; some experts reported seeing a boost in performance in the double digits by improving that data when they would sometimes see only a fraction of a percent of improvement spending the same time on model tweaks. Tuning the data became less taboo, and Data-Centric AI (the practice of iteratively applying changes to the training data) was born.
So where does DataPrepOps stand in all this? To put it simply, DataPrepOps is to Data-Centric AI what MLOps is to Model-Centric AI: a collection of pipelines, tools and best practices designed to enable data scientists to adopt a Data-Centric AI approach when training their models.
The end of the static training dataset
While much of the community grew excited about the Data-Centric AI movement very quickly, the true innovation that it brought is still rarely grasped and appreciated: Data-Centric AI puts an end to static training datasets. Preparing a dataset isn’t a one-time operation; it has not only become dynamic, but can also be undertaken live, as the model is training. This is a huge shift in paradigm that deserves to be highlighted. Managing data quality, too, has become a dynamic process.
Design Patterns for the Practice of Data-Centric AI
While Data-Centric AI represents a clear shift in the way data scientists approach model tuning and training, it might be harder to see why traditional MLOps workflows and tools are not capable of sustaining the new paradigm. If you refer to the first workflow, it seems after all that both Model-Centric AI and Data-Centric AI could share the same pipeline, and that the only difference would be what to put in the top box of the diagram. Both involve retraining the model, assessing the predictions, and making changes in order to improve them.
There is one major difference between acting upon the model and the dataset: when modifying a model, a data scientist is essentially dealing with one object (though a complex one); a dataset, on the other end, is a composite object, or more specifically, a collection of many objects called “records”.
In that sense, when one decides to make changes to the data, two steps are involved rather than just one:
- A step to decide what records to modify; this includes records that may not exist and need to be generated
- A step to decide what to do with this list of records. This includes selecting from an existing pool of data, adding them (either by collecting more or synthetically generating them), removing them from the dataset or modifying them (for example, by applying specific data augmentations or altering their annotation).
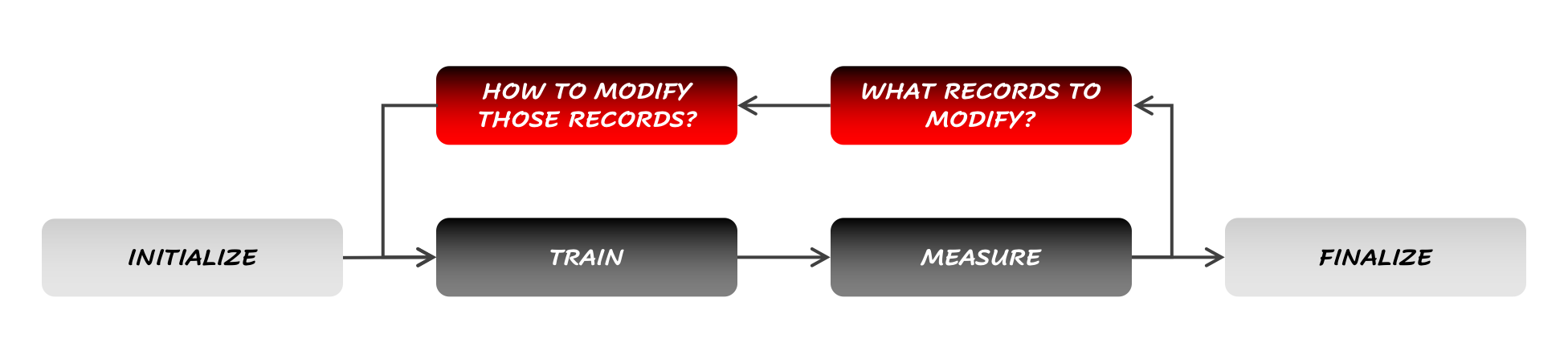
Figure 3: The general workflow for Data-Centric AI (DataPrepOps)
An example of a Data-Centric AI workflow could, for example, be summarized as: “Apply a horizontal flip on all records from the cat class”. In many cases, identifying which records to modify can be a lot trickier than deciding what to do with them, a difficulty that does not typically exist with Model-Centric AI.
That said, the workflow above is really a factorization of a series of microdecisions made at the record-level: in short, improving the model is a more tractable problem (for example, hyperparameter optimization in Deep Learning systems is NP-complete) than tuning every single one of the records of a dataset. This means that in its most comprehensive form, Data-Centric AI would involve parallel yet interdependent decisions about what to do with every single record, and hence, an entire neural network (!!).
Now while this workflow (even in its simplified form) might seem more complicated, it actually accommodates many popular concepts in Machine Learning, such as Active Learning and Active Synthetic Data Generation.
Active Learning, for instance, is just one of the many possible forms that can be taken by Data-Centric AI. Not all Data-Centric AI processes will involve Active Learning; Active Learning is only the case where some records are selected from an existing pool of unlabeled data, and then annotated before they can be appended to the training dataset.
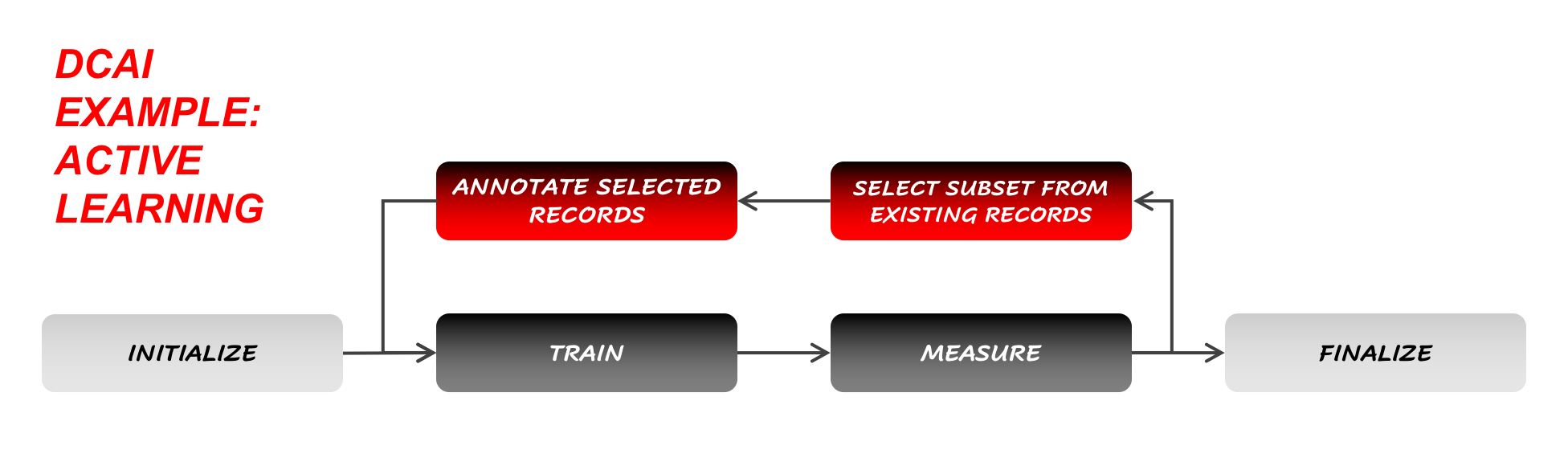
Figure 4: One example of a Data-Centric AI workflow: Active Learning
Of course, any Data-Centric AI workflow can also involve subworkflows, like one that would be designed to validate the annotations before those can be used and the training process can be resumed.
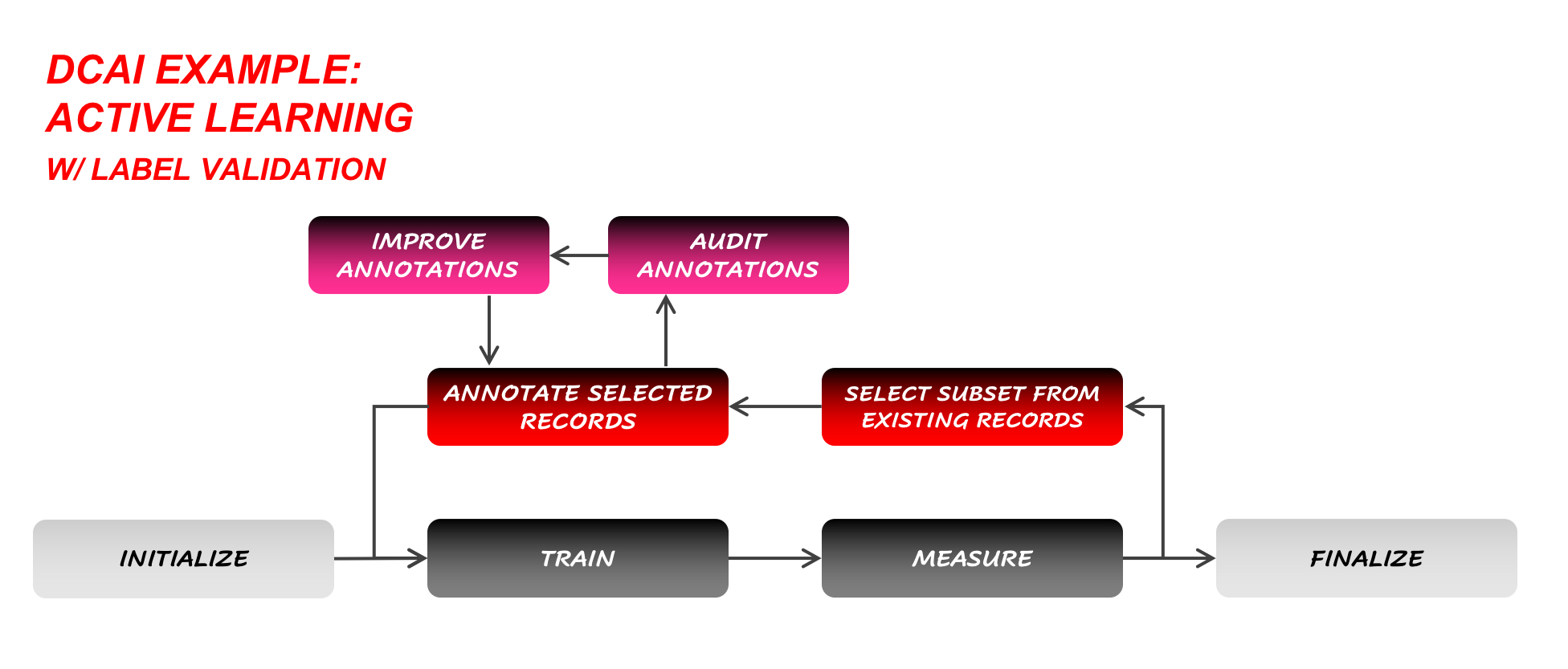
Figure 5: A more sophisticated version of the Active Learning workflow.
Another famous Data-Centric AI workflow is the case of (smart) Synthetic Data Generation.
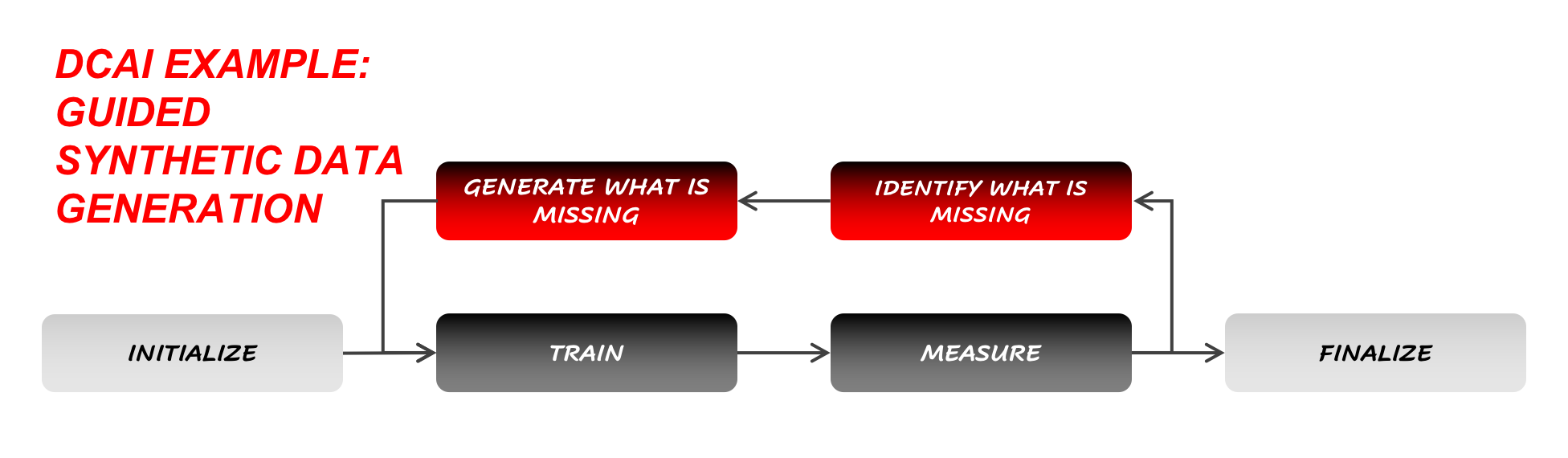
Figure 6: Another example of Data-Centric AI workflow: the Synthetic Data Generation
The Odd Cases of Human-in-the-Loop ML and ML Observability
Not everything that claims to be Data-Centric AI actually falls under the Data-Centric AI bucket. To qualify as Data-Centric, a workflow actually needs to:
- Support iterative changes to the training data
- Trigger those iterations based on the state of the model
This means that no matter how sophisticated the validation of the data might be, if it is not iterative and/or does not take into account the model, it cannot qualify as Data-Centric AI.
Therefore, contrary to popular belief, doing Human-in-the-Loop does not automatically mean you are doing Data-Centric AI; the only case where a Human-in-the-Loop approach would qualify as data-centric is when the decision to modify the dataset (which records and/or how) is based on the model, not on human input. The action of modifying the dataset (or, more commonly, the annotations) can still be performed by a human being.
The fact that the concept of ML Observability has also grown in popularity in the past 5 years naturally also begs the question: does it, or does it not, qualify as a specific implementation of Data-Centric AI? The answer to that question is a little less ambiguous than for Human-in-the-Loop labeling, as ML Observability does involve an update to the model after data drift is observed and an automatic signal to re-train the model is triggered. What makes the case for ML Observability as a use case of Data-Centric AI difficult, is the fact that the dataset is typically updated as one object: the model is usually completely re-trained using a newer, fresher training dataset instead of implying iterations on the same old dataset.
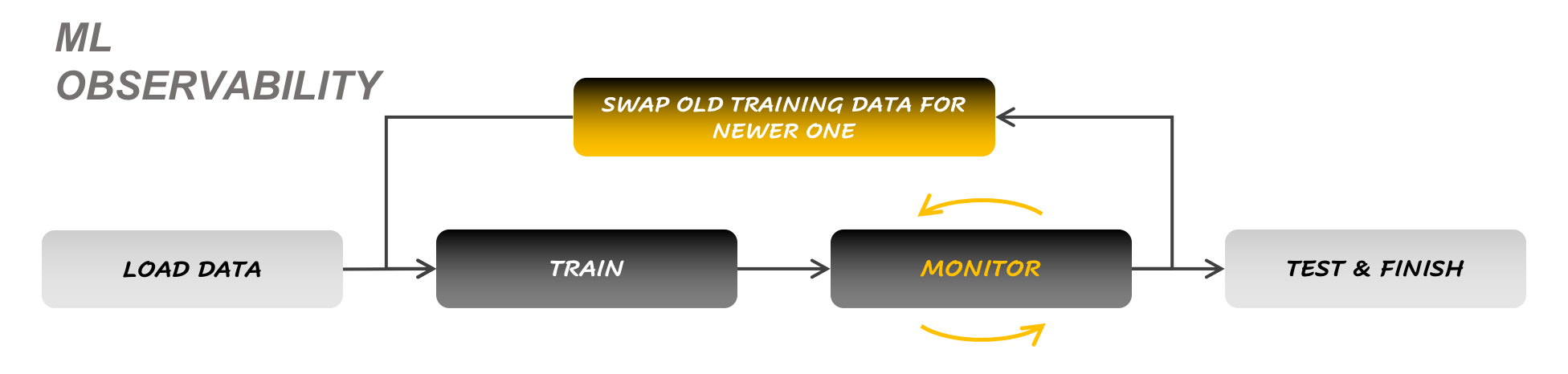
Figure 7: The workflow of ML Observability
Data Orchestration for DataPrepOps
Just like for the implementation of MLOps pipelines, a good Data Orchestration tool is necessary. There are additional challenges to account for in the case of DataPrepOps though, such as:
- The fact that in many cases (especially when manual data labeling is warranted), the pipeline needs to accommodate for pausing / resuming the pipeline without the risk of interrupting the entire flow and having to restart from scratch
- The ability to accommodate for additional (potentially record-level) granularity in the workflow
- Some support for conditional pipelines, since the data-centric piece involves a two-step process rather than a simple one
These functionalities do unfortunately not always come as a default with most data orchestration tools. For instance, after experimenting with many options, we at Alectio have opted for Flyte to support our platform.
With all this being said, DataPrepOps is a fast growing field at the intersection of DataOps, Data Engineering and MLOps, and there is much, much more to be said about it. In addition to the workflows, DataPrepOps also includes the proper implementation of each of the steps that could be included in a Data-Centric AI process such as data curation, data labeling or synthetic data generation. While this post was solely focused on the implementation of proper DataPrepOps pipeline, we cover many other aspects in other posts and encourage you to go through them to learn more about DataPrepOps in general.



0 Comments