
Evolution
“Deep Learning” — oh, I do have your attention now, don’t I? If ever there was an award for the Tech buzzword of the decade, Deep Learning would certainly be a top contender. One of the newest and most popular types of Machine Learning algorithms, Deep Learning is one of the biggest breakthroughs in the field, that mimics the function of the human brain using large networks commonly known within the community as neural networks. If we were to reflect on the contribution Deep Learning has made specifically in the field of Computer Vision the images below would be appropriate:

The impact of Deep learning on real world Computer Vision problems
One might wonder why research on Deep Networks suddenly took off this past decade, and not, for example, the decade before especially considering that earliest artificial neural networks date back to the 1950s. One thing is for sure: the arrival of powerful hardware machines such as GPUs, TPUs etc. did have a major impact in pushing Deep Learning to its maximum potential. Yet, the true “Eureka !!!” moment that brought the definitive attention of the ML community to Deep Learning might have been the ImageNet Challenge.
ImageNet is all you need
ImageNet was born in 2010, as a result of the efforts of Fei-Fei Li and other fellow researchers. The rationale behind the idea of putting together a dataset as large as ImageNet (over 14 million images with 1000 non-overlapping classes) was to enable the development of algorithms that could operate in the real world. Training such an algorithm would indeed require as much complex real world data as possible so that it could truly grasp the common traits within each one of the target classes and get to a more optimal decision boundary that separates them from each other. For example, if you were to build a dog detection algorithm but had only 10 pictures of dogs taken in your neighborhood, you detection system would most probably give you sub-par results. That’s because with those 10 images, the algorithm would not have been exposed to a large enough variety of dogs and would have a very restrictive view of what a dog is supposed to be, since the dogs in your neighborhood most likely do not represent a good sample of all the dogs that can be found in the world: that’s what data scientists call “overfitting”. On the flip side, feed your algorithm with the picture of every single dog on the planet and your algorithm might fail to find the correct patterns that summarize what a dog is: that effect is known as “overgeneralization”. This problem is most popularly known in the ML community as “Bias-Variance Tradeoff”.
But let’s come back to ImageNet: how come this dataset is considered such a major turning point in Deep learning? It all goes back to the ImageNet challenge, which ran from 2010 to 2017 and smashed all boundaries that were set by the previous classification algorithms from the beginning of time. A simple look at the results of the competition below shows the dramatic improvements made to image classification algorithms in just a few years.
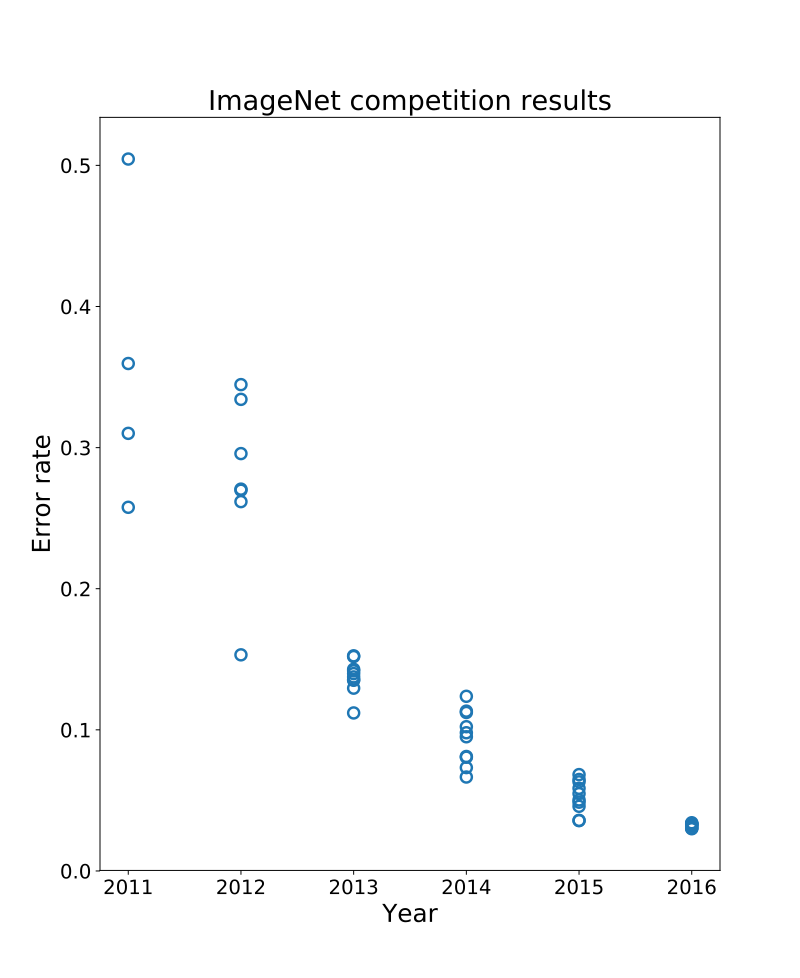
Source : https://en.wikipedia.org/wiki/ImageNet
According to the chart above, it is obvious that a significant shift occurred after 2012. Enter AlexNet! In 2012 the team of three researchers from the University of Toronto, Geoffrey Hinton, Illya Sutskever and Alex Krizhevsky, submitted a Deep Convolutional network architecture that broke the 0.25 error rate barrier on ImageNet; and for the first time ever, a computer got better at image classification than a human. Remarkably, they were the only team in the top 10 that year to use neural networks. The following years saw a huge shift in the error rate of the ImageNet challenge, as different versions of neural network architectures were introduced that kept breaking the limits of image classification and object detection, again and again. Also noteworthy: networks trained on ImageNet were found to be surprisingly useful for other classification and object detection tasks, a concept which was later coined as Transfer Learning.
Dissecting ImageNet
While the improved performance metrics obtained through the years prove that networks trained on ImageNet are far superior in performing in real world situations, recent research shows that networks trained using ImageNet are actually biased. In particular, some significant research shows that networks trained on ImageNet do in fact “cheat” to a certain extent by recognizing textures rather than shapes of objects in the images. According to the paper titled “ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness“, the following hypothesis was proven “ […] ImageNet trained CNNs are strongly biased towards recognizing textures rather than shapes, which is in stark contrast to human behavioral evidence and reveals fundamentally different classification strategies”. The image below shows an example from the paper:

Classification of a standard ResNet-50 of (a) a texture image (elephant skin: only texture cues); (b) a normal image of a cat (with both shape and texture cues), and © an image with a texture-shape cue conflict, generated by style transfer between the first two images.
The paper proves texture bias in standard CNNs and carries out a series of experiments to demonstrate that removing texture bias and introducing shape bias improves the performance of models in terms of transfer-ability and object detection.
Our experiments
The collaboration between Lab41 and Alectio started from a common desire to develop processes to improve the quality of any training set, and eventually, train better models with less data. The goal of our research is to combine Alectio’s expertise in data curation and Lab41’s work in synthetic data generation in order to boost the quality of any dataset, and we will tell you more about our work in future blog posts — so follow us to keep track of the next set of blogs along this line of research. Yet, a natural first step for us was to understand in depth how seemingly minor “tweaks” made to training data would impact the performance of a model; after all, if the incredible performance of Neural Nets in image classification came mostly from their ability to analyze a small detail such as texture, it isn’t hard to believe that distorting the training images could lead to potentially very interesting results.
It is in that spirit, and inspired by earlier research, that we decided to run some experiments aiming at analyzing how sensitive popular Deep Learning models are when it comes to simple image transformations. Given that models trained on ImageNet are believed to be the epitome of generalizability/transfer learning capability, we really wanted to know how resistant those were to the most basic image distortions.
In short, we set to answer the following three questions, two of which we will try and answer in this post:
- How sensitive are ImageNet trained models to simple image transformations?
- What transforms can easily be detected with a pre-trained model?
- Could such transforms be used to enhance a dataset? (that will be the subject of a future post)
The first step was for us to select a range of models pre-trained on ImageNet:
- Alexnet
- Squeezenet
- Squeezenet1
- Vgg16
- Vgg16_bn
- Vgg19
- Vgg19_bn
- Mobilenet
- Resnet18
- Resnet34
- Resnet50
- Resnet101
The rest of the protocol is actually as easy as it gets: we only transform the ImageNet’s training set and use the transformed dataset to evaluate the performance of the pre-trained models; in other terms, for each experiment, we use one transformed version of ImageNet, which we call I_t_i, as our test set. Yet, beyond its simplicity, it is a compelling experiment to study how ML models learn, and in particular determine for which classes they are overgeneralizing from only a small set of features/characteristics. It’s like you were to show a child a book full of horse pictures and later decided to come back and test the child on its understanding of the concept of a horse. To do this, you would print the same pictures in the book, except you would carefully transform them by flipping, cropping or coloring them in a different color. If the child failed to identify the horses just because the pictures were a little bit different from those they remembered from the book, you would naturally conclude that he/she had in fact memorized the pictures and would actually not have truly learned anything — and that is exactly the conclusion we will reach if/when our models fail to correctly predict the transformed version of an image originally present in the training set.
We applied the following simple transformations to every single image in ImageNet’s training set and then analyzed the impacted performance of our model:
- Rotation
- Brightness
- Histogram equalization
- RandomHorizontalFlip
- Translate
- Zoom
- Perspective
- RandomVerticalFlip
- Histogram equalization + Zoom + Brightness
Note that at this point we did not design any adversarial transformations to apply; this leads us to believe that the models should be mostly robust to any of those transformations.
Sensitivity analysis
To test how the model reacts to these transformations, we perform a two sided T-test. The metric that we take into consideration is class-wise (1000 classes) accuracy across all chosen models (12 models).
For our first T-test hypothesis we decided to use the class-wise accuracies of each model. Our control group in this case would be class-wise accuracy of all 12 models when no transformation is applied. Our experimental group would be class-wise accuracy of all 12 models when one of the transformations is applied.
We iterate through each transformation that we chose in order to see how the two populations compare to each other with respect to accuracy. Our null and alternative hypothesis in each case would be:

Picking a p-value of 0.05, we obtained the results shown below:
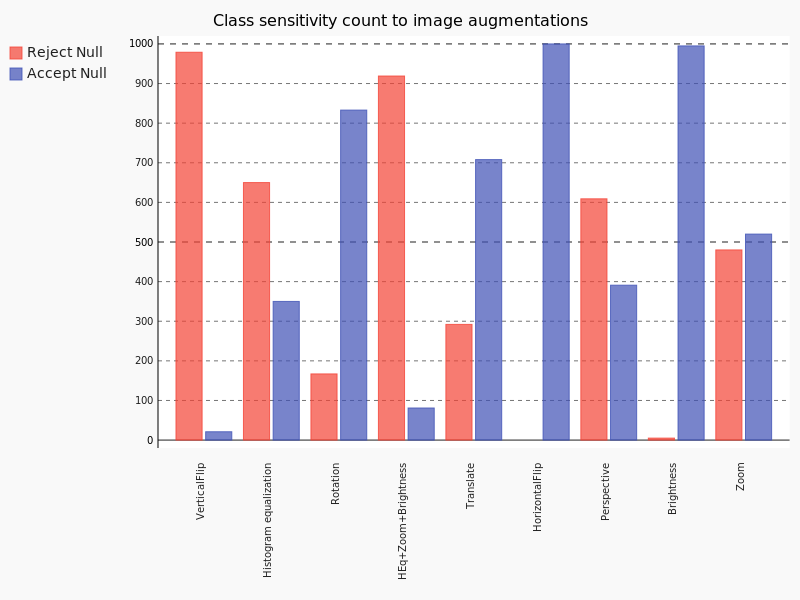
The above bar chart gives a quick overview of how the performance of classes compare with respect to each image augmentation. The sum of the blue bar and the red bar always adds up to 1000, which is the total number of classes we considered; however, a predominant blue bar would indicate that the models were mostly insensitive to that particular transform while a red one would indicate that the models are deeply impacted by the change.
Here are a few of the things that we notice right away:
- Horizontal flipping has no effect whatsoever, meaning that the pre-trained models do well against it, which was expected.

- The brightness adjustment value we chose seems to have little effect on each class as well. (Note : Extreme values of brightness (high or low) may or may not have effects)
- The highest impact was observed for rotation and translation.
- We also see that Zoom has pretty much a balanced effect meaning half the classes are affected by zoom and thereby making it harder for the model to detect them
- Histogram equalization seems to confuse the model quite a bit in most of the classes
- Applying Histogram equalization , brightness and Zoom together seems to be a harder combination as well
- Of all the cases Vertical flip impacts the model the most meaning the model fails to understand something if you flip a picture upside down.

We analyze out of curiosity a few samples that agreed to the null hypothesis we find the classes and sample images below.

A few samples that reject the null hypothesis are:

Do these results make sense ?
Even though from a human perspective we can clearly see that some of these make sense as to why they did/did not have an impact on the model’s performance, in order to validate these from the network’s perspective we would need to extend this study to look at how the decision boundary gets affected when these images are subject to Vertical flip transformation.
Repeating the above experiment to see how these augmentations affect the overall performance of the 12 models in terms of shift in accuracy, we see the T-test results below:
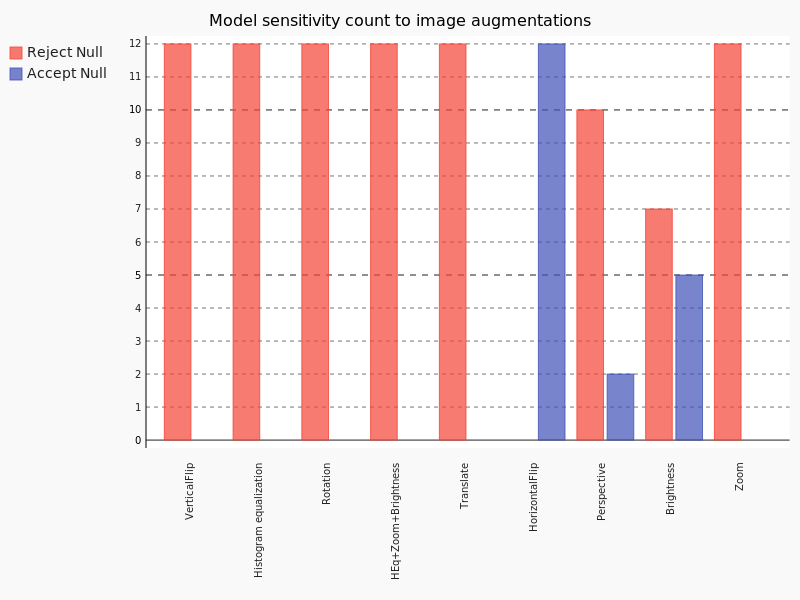
From the above bar chart it seems like:
- All model performances are impacted to a great extent by Verticalflip, Histogram equalization, Rotation, Histogram equalization + Zoom + Brightness (HEq+Zoom+Brightness),Translate and Zoom
- A significant fraction of models is impacted by perspective transformation
- Brightness seems to have a decent effect on more than half of the models chosen
- As expected Horizontal flipping shows zero effect in terms of shift in overall accuracy.
Conclusion and Next Steps
The preliminary research that we presented in that blog post actually brought us to interesting conclusions regarding the stability of well-known Deep Learning models against some basic transformations. It also opened new questions and directions for future research. For instance, whenever a class was shown to be sensitive to a particular transform, we can hope that same transform could actually be used to (adversarially) enhance a training set — or that we could, on the contrary, use that sensitivity as a way to identify unstable classes or even outliers and problematic data records, such as an image that was flipped by accident.
In future sequels of this post, we will show how we combine simple image transformations with more sophisticated ones both to identify what we call “hurtful” data within a training set, and to attempt to fix those same hurtful records.



0 Comments