
The year is 1965. Lyndon B. Johnson is sworn in as president. The Rolling Stones releases “Satisfaction,” their first number one single in the United States. Vietnam War protests grow in size and frequency. Canada adopts its familiar maple leaf flag. And the first desktop personal computer is released by Olivetti. It’s called the Programma 101 and it’s essentially a Very Large Calculator. It costs about $26,000 in inflation-adjusted dollars.

This cost more than a car
It is also the year Gordon Moore, co-founder of Intel, predicted that the number of transistors in silicon chips would double every two years. This is Moore’s Law. In practice, Moore’s Law meant that computers would increase in power and decrease in relative cost at an exponential pace. And for more than 50 years, Moore’s Law held up.
That’s over now.
You can find plenty of people who understand this. The CEO of Nvidia, for example, said “Moore’s law is not possible anymore” last January. The MIT Technology Review agreed a few weeks back. Horst Simon at the Lawrence Berkeley National Laboratory has noted the highest-end supercomputers aren’t keeping pace with Moore’s exponential prediction. The list of smart observers goes on and on but you get the idea. And while the end of Moore’s Law doesn’t mean the end of progress in computing, what it does mean is that you can no longer forecast continued, predictable improvements.
Now, let’s contrast this with another, more recent development in computing: Big Data. For the past couple decades, we’ve seen an explosion in both the amount of data we create and the amount of data we’re storing. According to an IBM study from last year, 90% of the data on the web has been created since 2016. As the preponderance of internet-connected devices increases and more and more people spend more and more time online, it’s a safe assumption that data creation isn’t going to slow down significantly for some time. The International Data Corporation (IDC), for one, predicts a compounded annual growth rate of data at 61%.
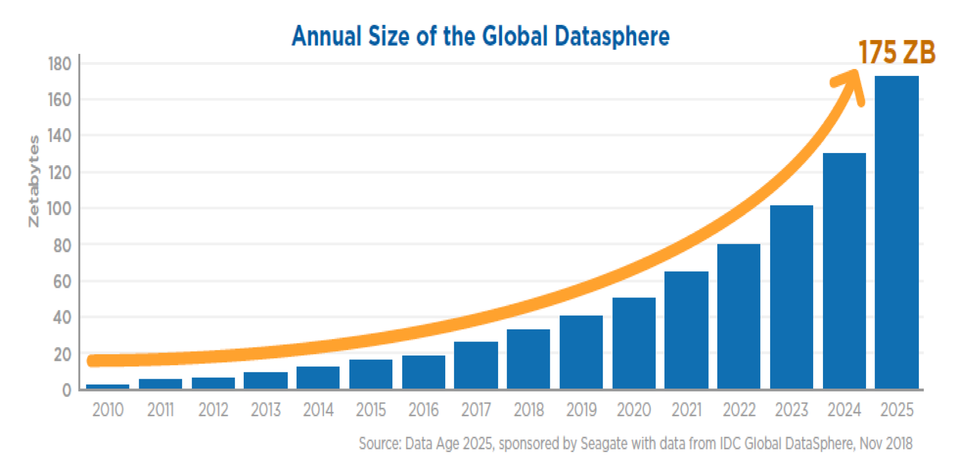
From the IDC study linked above, a look at the ballooning global data cache
Which brings us back to the storage component. If we’re creating ever more data (much of which is memory-greedy data to begin with) but compute speeds and server capacity can’t keep pace, it’s not hard to forecast a day when we simply can’t store the amount of data we’re currently accustomed to. To use an analogy we’re all probably sick of, if data is the new oil, we’re heading towards a world where we have an unfathomable amount of oil but not enough pipelines or barrels to move and store it.
Of course, that’s not to say we’ll have no storage or anything close to that. But it does make sense that the demand for storage will increase and attendant to that, so will its cost.
So what does this mean for Big Data? It means the end of it, at least in the way most companies conceive of Big Data now. Because let’s face it: a lot of companies are simply hoarding data. Companies park data they never really look at in cold storage. They spend time moving and recataloging it. They deal with the security issues that come along with data hoarding. But many aren’t truly leveraging all that data for business processes. They’ve just been convinced that storage is cheap and plentiful, so why not save it? After all, you never know when it’ll come in handy.
The question companies will soon need to ask themselves is if storing all that data is worth it. If storage space and compute costs rise, hoarding data you’re not analyzing or using becomes difficult to justify. We need to move from an era of Smart Data, not Big Data.
Smart Data means making choices about our data, not hoarding it. It means keeping what we need and, yes, purging what we don’t. It means understanding the difference between data that is utile and valuable and data that’s redundant or harmful to your data and machine learning projects.
Additionally, as compute and server resources grow in cost, companies are going to have to make similar decisions about how they train their machine learning models. Brute force and the over-reliance on massive datasets should become more expensive and less popular while approaches that use less data (smart data) to train quality models should find themselves growing in popularity. Think about methods like active learning, where a model actively chooses which data will help it improve most, versus more traditional supervised learning approaches that prioritize endless streams of labeled data. Simply put: models that need less data to be successful are the ones that will thrive in a world where less data can be stored efficiently.
The end of Moore’s Law is a great time for all of us to take a step back and think about how our organizations are handling the data we have today and how we’re planning on storage and analyzing the data we’re creating tomorrow. As the amount of data in our society increases and the availability of compute and storage decreases, data and machine learning projects will become more expensive, forcing us to make the sort of decisions we simply don’t have to make now in a world where data storage is effectively endless. But the sooner you start preparing for the end of Moore’s Law, the better you’ll be. After all, it’s already over. And the demand for compute and storage will be catching up with supply sooner than most people think.



0 Comments