
Let us introduce you to DailyDialog. DailyDialog is a manually labeled, multi-turn dialog dataset covering a whole host of emotions, topics, lengths, and types of statements. This dataset includes stuff like casual chats about the weather, couples negotiating about where to go on vacation, people haggling over who owes how much for dinner, and a whole lot more. A quick example:
1: I have made up my mind. I am getting a tattoo.
2: Really? Are you sure?
1: Yeah! Why not? They are trendy and look great! I want to get a dragon on my arm or maybe a tiger on my back.
2: Yeah but, it is something that you will have forever! They use indelible ink that can only be removed with laser treatment . On top of all that, I have heard it hurts a lot!
1: Really?
2: Of course! They use this machine with a needle that pokes your skin and inserts the ink.
1: Maybe I should just get a tongue piercing!
Now, setting aside that you really ought to give a tattoo a little more thought than this, this is a really solid, open source dataset that spans a fairly largely swatch of conversation and statement types.
It’s also a dataset that helps argue you need a data collection strategy.
Let’s start by looking at the test set. More importantly, let’s talk about the distribution of the 2624 sample test set:

What should first jump out to you is how imbalanced that set is. There are only a small handful of “culture & education” labels versus “work,” “ordinary life,” and “relationship” ones. And while some might make the assumption that the accuracy of our models would correlate with the amount of examples we had to train on, what we found was quite different.
We used active learning to monitor our model’s performance over 10 loops of this imbalanced training training set. In the graph below, you’ll see the normalized accuracy of each loop for each class, organized by abundance. To put that another way: the classes on the left had the most examples, while the classes closest to the right had the least. Here’s where things start to get really interesting:
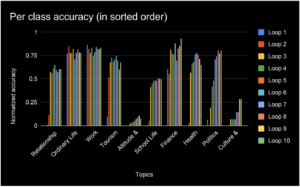
Classes with the most examples from the test set are on the left
See the “finance” class? That had a mere 76 samples out of over 2600 (or about 3%). And yet, by our last training loop, finance had the best accuracy, better than classes that boasted nearly 900 records for our model to learn from.
So what can we extrapolate from this? First, that representativeness is not the same as usefulness to a model. In other words, your model doesn’t need to see a representative amount of each class to understand it. Some classes are simply easier to learn than other classes are. Some features are simpler than others.
Using active learning, we also noticed that our model changed the distribution of data it was asking for across loops. We noticed a similar pattern when working with our customer Voyage, where the model was greedy for pedestrian data in the beginning of the learning cycle, so greedy in fact that it actually ran out of good examples as training went along.
Now, take those two conclusions together and start to think about what that means for your data curation and collection efforts. It’s not enough (or really, it’s not optimal) to simply collect as much as you can in hopes of improving your models. That’s because not all data is equally useful. In the case above with DailyDialog, you’d likely shy away from feeding your model more and more financial data. In fact, the model understood that class on just a fraction of the data.
It’s worth noting that we noticed some interesting phenomena outside of just the class accuracy. For example, we found that the model had preferences around sentence length and learned certain types of statements (like questions or directives) at different rates as well. Finding the ideal learning strategy for your project involves combining all these various inputs and collecting the right data as you move along, not optimizing for a one simple category.
In the real-world use case of Voyage, we found that their model was greedy for pedestrian data. But think about what that means from a business perspective: since the model needs pedestrian data, they can simply go out and collect more! That means less time sitting in traffic on the highway and more time driving in the city, finding data full of people walking around instead of cars idling (though, even then, not all pedestrians are created equal here either. A single person in a frame is easier to learn and less informative than a frame with two people walking side-by-side with some occlusion). The point is: understanding the model informs can inform their data collection and allow them to save a ton of resources all while improving their model because of it.

An information-dense but more complicated frame than a single pedestrian in a crosswalk
At Alectio, we’ve developed a wide range of querying strategies to uncover exactly this information. We mentioned a few last week talking about our work with the DeepWeeds dataset, but that’s just the beginning. Finding the right querying strategy for your models means understanding what your model learns quickly, what your model needs more of, and then reacting to that information. You can leverage that information to curate what you feed your models and what your organization collects and labels.
Because, let’s face it, a lot of our organizations don’t really have a fine-tuned data collection strategy. The strategy is usually “we should collect all the data.” And in fairness, that’s ideal (and inherent) for some applications (recommendation systems, for one). But for most ML practitioners, understanding what data is most useful to their models means better understanding of that model’s learning process, getting to higher accuracy more quickly, and prioritizing collecting and curating what matters most. That means better performance in less time for less money. And that’s never been a bad idea.



0 Comments