
Active learning is one of the most misunderstood techniques in machine learning. Many of us had some experience with it in school, using those well-curated academic datasets but few people use it in the business world to handle real-world data with all its messy complexity.
Here at Alectio, we think active learning techniques are unfairly maligned and potentially game changing for certain problems not in academia but in industry. A big reason for that is that active learning has the promise of significantly reducing the cost and time it takes to train production-ready models. Our research suggests that active learning can deliver the same (or better) performance as standard supervised learning does while using just a fraction of the training data.
In this piece, we’re going to dispel a common myth about active learning and give you a framework to understand if active learning is feasible for your projects.
Let’s start by defining what active learning actually does. Generally, active learning models start by learning from a random sampling of data, after which the model actively requests more labels to improve its performance.
What’s missing from that definition is what kind of data the model requests after training. And that’s for a reason. There are a ton of different sampling techniques you can use for active learning but what we’ve found here at Alectio is that almost everyone we talk with assumes that active learning uses least confidence sampling. That is, it requests labels for the data it’s least confident about so far.
And while sampling from least confident data is a common strategy, it’s not the only strategy. And moreover, it’s often not a very successful one. That’s because oftentimes, the unlabeled data about which the model is least confident is, to put it plainly, spammy data. For example, if you’re training a facial recognition algorithm, the lowest confidence data might be cartoons of people’s faces or hopelessly blurry selfies. If the model ingests more of that data, it’s not going to get more accurate. Chances are, it will do the opposite. And if you write off active learning for your project right then and there, well, you’re making a mistake.
Let us show you why.
Earlier this year, we did an experiment on DeepWeeds. DeepWeeds is an open source dataset containing a little over 17000 labeled images of eight different weed species. We wanted to see if active learning would work for image recognition tasks on this data set, so we did a quick feasibility experiment.

First, we randomly segmented the dataset into five equal buckets–so with 17,000 data points to start with, that’s about 3400 per bucket. Then we trained our model on each of those subsets individually, first on a random sample of 20% and tested it for accuracy, precision, and recall. We did the same on a random 40%, 60%, and 80%.
Here’s one of those tests:
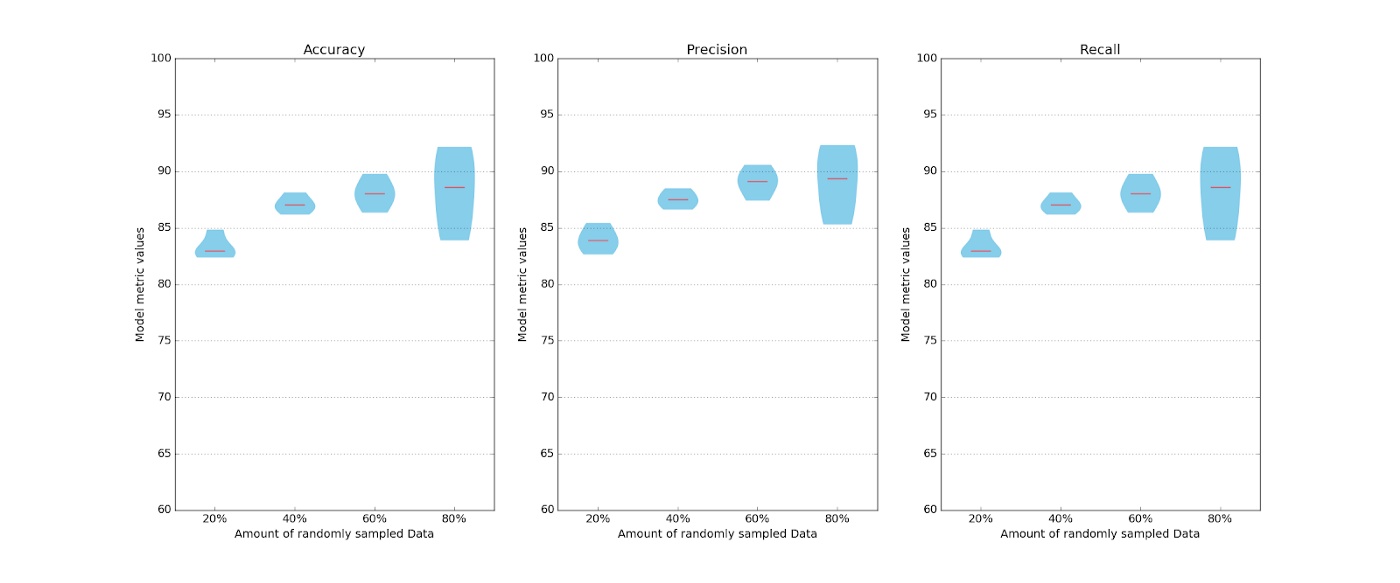
What we want to draw your attention to is something notable in the accuracy graph. Notice how much overlap there is between the 40, 60, and 80 percent tests? Moreover, notice how the best performance of the 20% test is actually higher than the worst performance of the 80% test?
Those are the exact sort of results that suggest active learning will work for this problem.
Why? Because the performance of this model isn’t based on how much data we train it on. Instead, it’s based on what data we train it on. Again, the best random sample of 20% gets us about 85% accuracy, whereas the worst random sample of 80% comes in below that. This suggests that if you sample the right kind of data, you’ll get better performance than simply sampling randomly.
And that’s a major strength of active learning: it isn’t trained on random samples. Instead, it selects what data it needs labeled so it can improve its performance. How it does so is based, however, on the sampling strategy you choose. And that’s where we’re going to circle back to that common misconception that active learning uses primarily (or only) the strategy of querying the data it’s least confident about.
See, when we used a least confident sampling strategy on this data, the results looked like this:
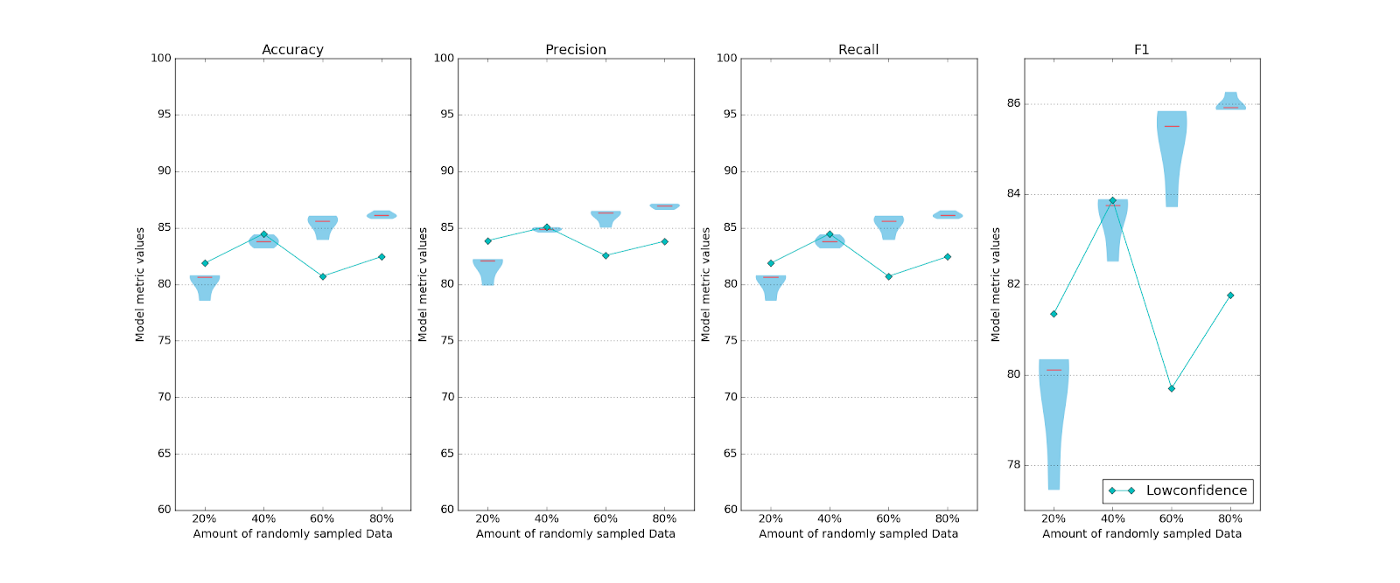
Least confident sampling results were…not promising
Not good.
What’s more, this is an open source, academic dataset — there’s not a lot of pollution or noise here. And even then, using a least confident sampling strategy gave us poor results. Our model’s performance was changing erratically and more data didn’t necessarily lead to better accuracy.
If you’re like a lot of machine learning practitioners, you might move onto a completely different strategy and write active learning off here. What we decided to try was the same active learning models with a few different sampling strategies. And here’s how those looked:
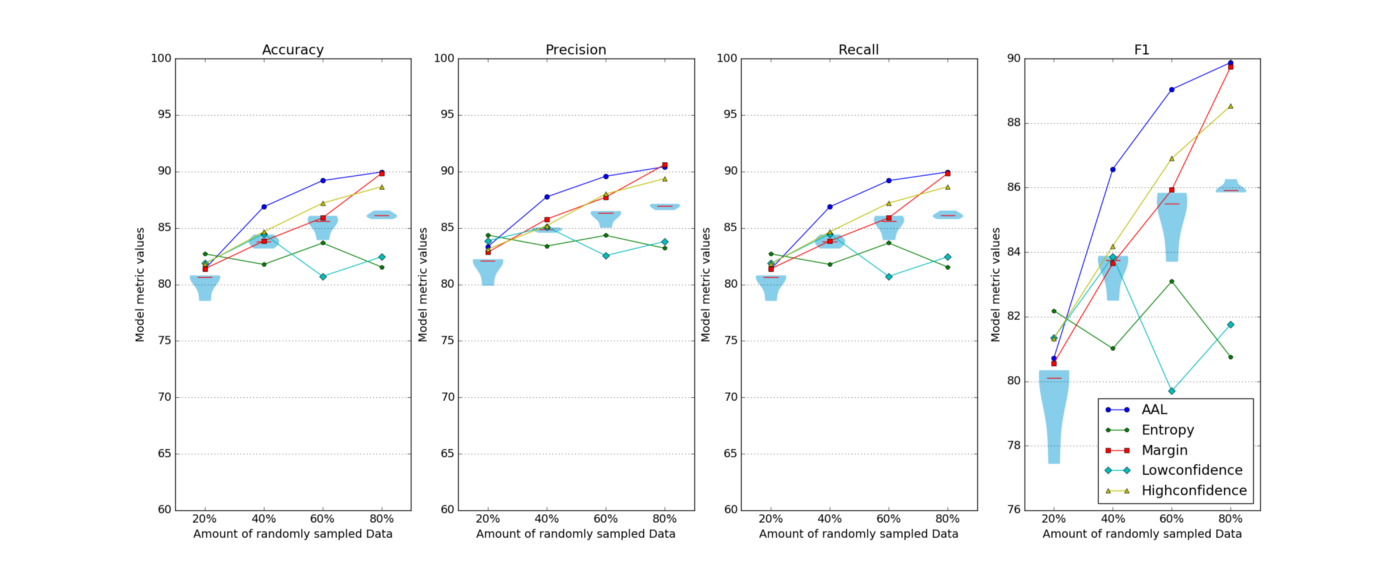
That’s more like it
Much better, right? While the least confident technique was worse than random sampling in most runs, other sampling methods were much better than random. This again suggests that active learning is not just feasible for the problem but actually quite promising.
It’s also important to point out something that might be obvious to some readers but we want to underline it here before we move on: data scientists and ML practitioners don’t just have machine learning budgets and compute constraints. We also have labeling budget constraints. Active learning holds the promise of selecting the right data for labeling, not labeling random swaths of potentially useless or even harmful (spammy) data. That in turn leads to better model performance with less training data. And you probably don’t need us to tell you what a good thing that is.
In our next installment, we’re going to dig into each of those sampling techniques and talk a bit more about them, but what we want you to take away from this first part is this: don’t fall into the trap of assuming all active learning processes rely on the same sampling strategies. They don’t. The feasibility study like the one we ran is fairly simple to try and if you’re seeing that a 60% sample has the same or less accuracy than your 20% or 40% samples, that likely means active learning can work for your project.
Because for projects like that, it’s about finding the right training data, not the most training data. And that’s exactly what active learning does well.



0 Comments