
Explore-exploit is a paradigm that goes way beyond Machine Learning; it is actually the conceptualization of an everyday dilemma that we face at almost every instant of the day when we make even the simplest decision. The human brain is wired to seek predictability–most of the time. Until, of course, we get bored and start dreaming of breaking the routine.
Assume you come home from work after a hard day at the office. You have only one thing in mind: relax with your favorite pizza from your favorite restaurant; the last thing you’d want to happen at that point in time would be to be disappointed by your food, and so you’re a little risk-averse. You’re in “exploit mode”: you’re exploiting your knowledge of what food makes you feel better.

A few days later though, you might feel more adventurous, and might want to try a new dish in hopes of finding something you like even more. That’s the “explore” phase. If the new dish turns out to be disappointing, you will know your old fave is still the way to go. But if it turns out to be even better than your old go-to? Now you have a new favorite to exploit when you’re having a bad day.
This explore-exploit paradigm is at the center of reinforcement learning, a category of ML designed so a machine can discover “what works” by alternating between exploration and exploitation instead of learning from historical data. Here, instead of training a model with existing data–as would be the case for supervised machine learning–an ML scientist would simply have to pick a parameter between epsilon 0 and epsilon 1, representing the willingness of the agent to take risks, and a reward function, designed to proxy the consequence of a good or bad outcome on the agent.
Explore-exploit is also an incredibly important concept in artificial general intelligence as it gives a path for a machine to truly learn on its own, by allowing it to be curious and learning from the consequences of its own choices.
What’s the relationship to learning?
Before discussing how explore-exploit also plays a role in semi-supervised learning, let’s discuss how explore-exploit relates to the topic of learning.
Learning, fundamentally, is about getting outside of one’s comfort zone and being exposed to new things. If you keep reading the same book or taking classes on the same topic, you won’t learn much. Sure you’ll know that one book inside and out, but that’s learning time that could be better spent.
At the same time, learning is also about retaining knowledge: have you really learned anything if you forget that newly acquired knowledge after a few hours? Learning is also about exploring your existing knowledge: students know that when they practice a skill that they already have.
Which means that learning is actually a balancing act between exploration of new concepts, and exploitation of existing knowledge. You could even say that the best learners are the ones who know how high they can set their epsilon without losing any of their existing knowledge.
The relationship to active learning
While explore-exploit is the core of reinforcement learning, it also has very interesting implications for semi-supervised learning as well.
At Alectio, we have augmented concepts in active learning–which was originally designed to help ML scientists reduce the amount of labels they needed to train their models–to make active learning into a tool to study how models learn.
While active learning still seems to intimidate a lot of ML scientists in the industry, it is actually surprisingly simple concept: instead of feeding an entire dataset at once, you start with a small batch of data which you will use to train an initial version of your model, and you will then use this rough model to find out what to feed the model next.
The logic used to determine this next batch — called a querying strategy — is normally pre-set by a human. In most cases, ML scientists simply run an inference step on the “unpicked” data and select the records predicted with the least confidence (a proxy of high model uncertainty) in an effort to focus on the part of the data that the model seems to struggle with.
This, of course, is a pure “explore” strategy, and–spoiler alert–it usually doesn’t work very well, especially with industrial data. That’s both because by focusing only on difficult data, the model is more likely to forget the things it knows already, and also because not all “explore” strategies lead to discovering valid “opportunities.” For example, a model exploring only the least certain data may focus on a subset of your worst, spammy data, leading to decreased performance and confusion. There’s potential for your model to not only fail to learn something valuable, but also forget what it already knew.
For a lot of machine learning scientists, least confidence sampling is synonymous with active learning. They are one in the same. But that’s incorrect. It’s too simplistic a way to think about active learning and it shorts what active learning can achieve.
For starters, there are plenty of other sampling strategies that you can experiment with and the results you get from these are often dramatically different. In fact, we recently took a look at a handful of strategies for an image recognition task to evidence this exact fact. And, as you can see below, the least confident sampling strategy was a much poorer performer than other simple sampling strategies.
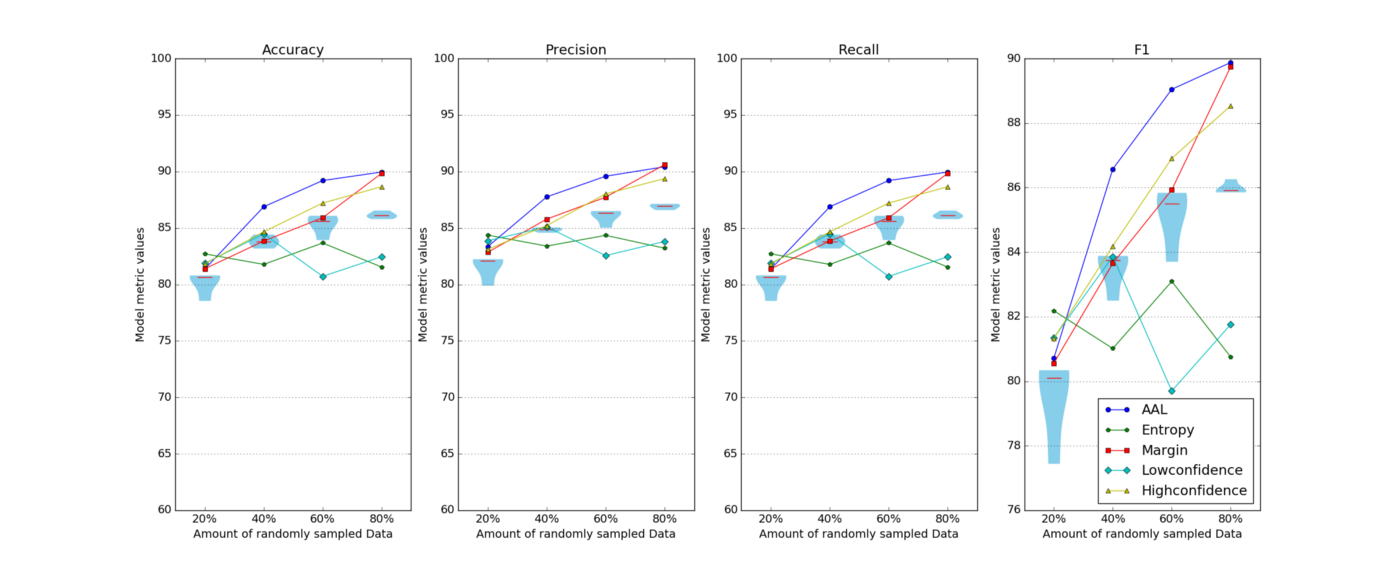
But still, that’s not all. There’s no particular reason you need to stick with the same sampling strategy over each subsequent loop of active learning process. As your model learns, your strategy can (and should) evolve.
Which brings us back to the explore-exploit paradigm.
At Alectio, we use reinforcement learning to find the optimal querying strategies for active learning. That means, instead of sticking with a single, simple strategy we evolve that strategy over each successive learning loop. We do this by finding the best balance between exploiting what the model knows and exploring what it needs to learn. Our strategies are dynamic and adaptable and change based on what the model needs most at any given loop in the process.
And yes, that’s a complex, intricate process! But it’s one we’ve seen pay dividends in our research on academic datasets and for our customers on industrial data. It works. And it works well. Active learning with dynamic querying strategies reduces the cost and time of training a model, necessitating less training data and labeling cost. Additionally, it can give you key insights into which data your model really needs and flourishes with so you can update your data collection and curation efforts to improve its performance even further.
If you’re interested, we’d love to show you what we’ve discovered.



0 Comments