
The Origins of Data Labeling
Remember the last time you took a picture with your friends to post on social media, and the app helped you save time by automatically tagging everyone for you? It might be hard to believe, but not so long ago, letting an AI identify faces on a picture was nothing but a distant dream.
The field of Computer Vision (the ability for an AI to extract information from images), actually originated in the 1960s with Larry Roberts’s Ph.D. thesis, and is considered by many as the stepping stone to Artificial Intelligence. And yet, it’s only in the early 2010s (half a century later) that the field started flourishing, and Computer Vision-based apps began to appear on the market. What happened to cause this mind-blowing delay?
The fundamental reason can be summed up in one word: hardware. Regardless of how impressive the early advances in Computer Vision were at that time, the necessary hardware to train sophisticated models and collect data was decades away from being invented. That led to a succession of AI Winters, until the GPU was finally invented in 1999. Once hardware advances eventually caught up with the needs of AI researchers, things started moving faster, and what was once pure theory could finally be put into practice.
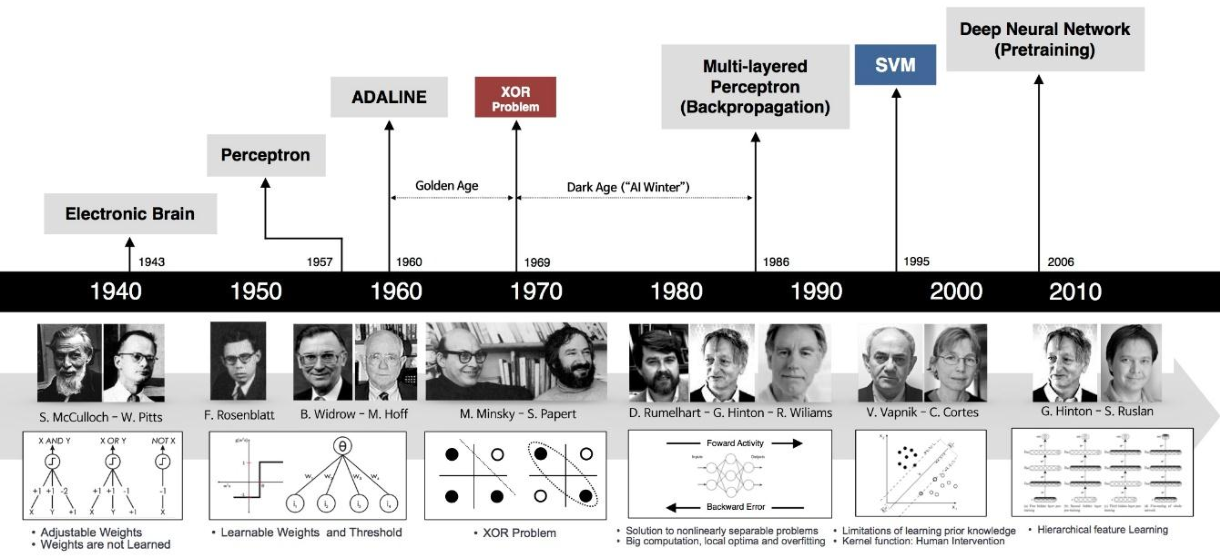
Figure 1: A brief history of neural networks and deep learning.
Computer Vision research took off a few years later, from 2009, when Fei-Fei Li and her team at Stanford released ImageNet: the first fully annotated open-source image dataset. Thanks to ImageNet, researchers worldwide suddenly had a baseline dataset to develop and test new model architectures. It took just 6 years before a model could outperform human capabilities when recognizing objects from pictures.
The industry soon realized that ML research not only required large amounts of data, but also needed that data to be annotated. That proved to be a challenge, since the size of datasets could easily reach millions of records. Thankfully, a few companies rose to the occasion and decided to provide labeling services to the rest of the industry. The slow and tedious task of labeling data was not incumbent on data scientists and ML researchers anymore; the data labeling industry, which is expected to exceed 8 billion dollars by 2028, was born.
While the data labeling business seems lucrative, it is by no means easy. While some use cases – such as pedestrian or lane detection, sentiment analysis or speech recognition – do not require expert labelers, others might require medical experts (if the data is made of x-rays or MRIs), surgeons (if the data consists of videos of open-heart surgeries), lawyers (if the data is a collection of legal documents) or geophysicists (if the use case focuses on predicting the presence or absence of oil in the ground), and those experts are just as expensive to hire as they are hard to find. With all that said, it is just the tip of the iceberg. Another way data labeling can be challenging, would be tasks such as search relevance or content moderation – when no absolute ground truth can be determined, and subjective judgments are required. An example would be how half a group of people find a certain video offensive to show to a 5-year-old, but the other half believes that it is appropriate to show them. Without further context, how can you decide which group is right?

Figure 2: Certain annotation tasks, such as object detection, can be particularly tedious and time-consuming.
It wasn’t long until both labeling companies and the ML researchers relying on them learned the hard way that accurately annotating data for a third-party was not only challenging: it was close to impossible. How could data scientists effectively communicate the requirements to people who ultimately wouldn’t be the ones developing the models? How could they efficiently audit and iterate on the work with the annotators? And how would labeling companies perform the work at scale, at a satisfactory pace without compromising labeling quality? All those questions remain unanswered to this day.
So over the years, the data labeling industry slowly expanded its scope and started exploring alternative solutions. Some companies began promoting the automation of data labeling with pre-trained Machine Learning models, an idea that can only be implemented for use cases where such models exist. It can be frowned upon by researchers as any bias would ultimately be transferred from the autolabeling model to the customer’s model. Others, even bolder, decided to benefit from a new technology called generative adversarial networks (GANs) to synthetize data from scratch. Parallely, the maturing labeling industry started adopting the more cost and time-efficient paradigm of Human-in-the-Loop labeling, inspired by the famous Pareto Rule, as a way to let human annotators focus on the higher-impact or harder-to-annotate data.
As the labeling industry keeps evolving, one certainty remains: building highly performant models requires high-quality data, with extremely accurate labels. At this point, we’re yet to develop the data preparation technology and processes to provide an efficient and scalable way to enable data scientists across the world to build the next generation of AI applications.
Read next:
– Part 2: What is DataPrepOps?
– Part 3: The Many Flavors of DataPrepOps
References:



0 Comments
Trackbacks/Pingbacks