
What is DataPrepOps?
Half a century went by from the inception of the fundamental principles of AI, to the day where AI applications finally saw the light of day. The 2010s finally marked the beginning of a new era for ML experts after two major AI winters. By 2015, ResNet already outperformed humans at identifying an image’s content.
While AI research was heading into full swing to the delight of practitioners, another storm was already brewing as industry leaders, and executives everywhere started showing signs of restlessness: where had the hundreds of millions of dollars they had spent on AI development gone, and why were they are hardly seeing a return on investment? Data scientists quickly went from having what was labeled the sexiest job of the century, to being viewed amongst the C-suite with skepticism. Data science leaders were blamed for their incompetence, which got some wondering: was another AI Winter just around the corner?
The issue was not in the modeling capabilities of data professionals; it had much deeper roots in the structure of the organizations they were operating within. There was an issue that no one had seen coming: while data scientists were doing an amazing job at developing models, they just didn’t have the relevant experience to push those models to production, and turn them into actual data products. Since companies did not anticipate it, they failed to provide the necessary engineering support to enable those ML projects into products that would turn a profit. Upon this realization, the most agile organizations trained DevOps engineers to take over those models and productize them for the data scientists. They quickly became known as MLOps engineers. The others that did not jump on the bandwagon, decided to rely on a new category of ML companies providing specialized platforms and solutions to automate that deployment process: the MLOps field was born.
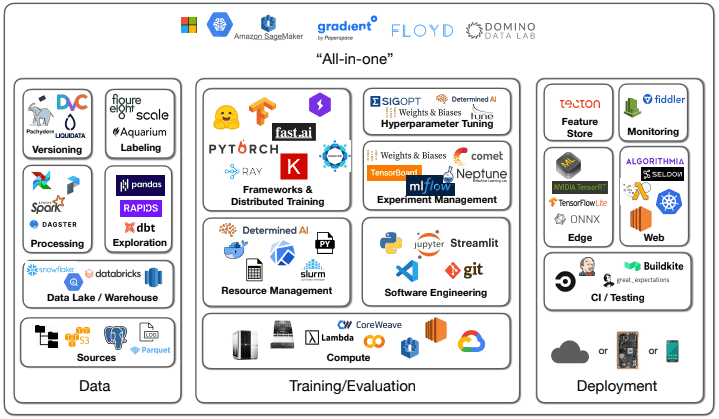
Figure 1: The complex MLOps landscape in 2021
The field evolved quickly, with MLOps startups popping up everywhere. At first, it helped bridge the gaps in the machine learning lifecycle. Then, the field gradually offered additional support to most aspects of ML development, from model architecture to model tuning and monitoring. One huge gap remained though: while data scientists were overwhelmed by data modeling and serving options, only low-tech data annotation solutions existed. The revolution that facilitated and automated data preparation was yet to come.
That’s where DataPrepOps comes into the picture; at a high level, the goal is to automate and operationalize the preparation of a training dataset, similar to what MLOps did for modeling a few years before. At its core, DataPrepOps is about leveraging science and technology (including machine learning itself) to streamline data preparation. The only thing left to do, was to figure out how.
There are two pieces to the machine learning puzzle: the data and the model – nothing new here! ML suffered from insufficient data, the modeling part somehow took the front seat. Most data scientists admit to disliking data preparation, and as a consequence, modeling became the sole focus of ML research. Even college students today are barely taught a thing about data preparation.
Automating data prep will require challenging the status quo. It would require putting data back at the center of data science and of the ML process, and to draw the attention of ML researchers on data preparation. After all, some of the best researchers, including Andrej Karpathy, had already acknowledged that improving data could improve the model by close to an order of magnitude larger than by tuning the model.
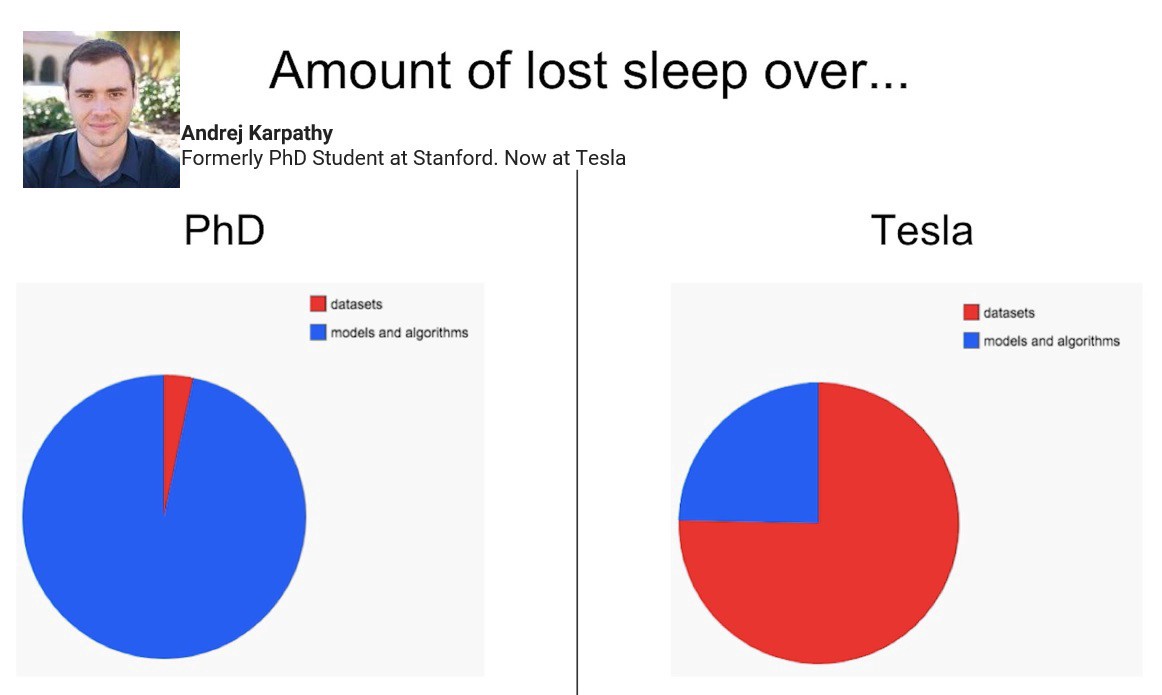
Figure 2: Slide “stolen” from one of Andrej Karpathy’s talks. During this talk, he described how spending time on data preparation was better for the return on investment of ML projects.
This is what Data-Centric AI is all about. Contrary to the traditional model-centric approach, where model performance is improved by tuning the model, data-centricity proposes that the dataset should be modified and tuned in order to get higher performance. When adopting a data-centric strategy, data is to be treated as the first citizen in data science, and machine learning is no longer considered a static, immutable object – it is to be augmented, relabeled, cleaned and improved until the data scientist is satisfied with the results. As a dynamic object, it requires the same fundamental elements leveraged by MLOps to operationalize model tuning and deployment – think hyperparameter tuning, monitoring and versioning solutions, but centered on the data instead of the model.
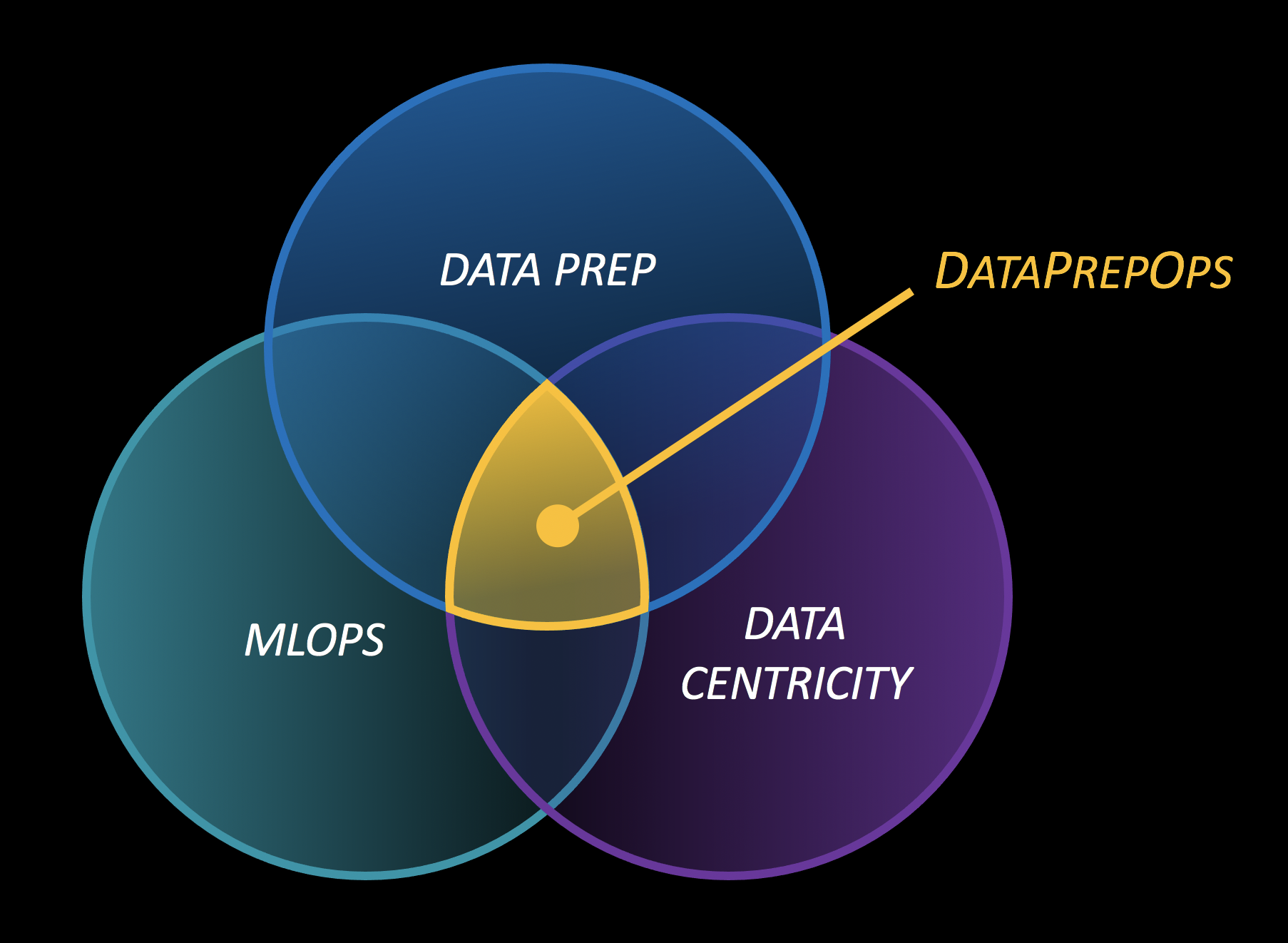
Figure 3: DataPrepOps is the operationalization and automation of the process of preparing data for ML. It combines the traditional element of model-centric MLOps with the new data-centric AI paradigm.
In other terms: DataPrepOps is simply MLOps for Data-Centric AI. It requires the development of an entire workflow designed to automate the preparation of a dataset, the same way that a traditional MLOps solution would automate the preparation of the model. When DataPrepOps reaches maturity, we can expect it to have the same impact on Data-Centric AI as MLOps had on model-centric AI a few years back. The true value of DataPrepOps for Data-Centric AI is evident, but how much the AI community embraces it remains to be seen.
Read next:
– Part 1: The Origins of Data Labeling
– Part 3: The Many Flavors of DataPrepOps
References:



0 Comments
Trackbacks/Pingbacks