
In the first part of this mini-series, we have taken a high-level approach to explain the mechanics of Active Learning, and have also emphasized that there were many things to be tuned when trying out Active Learning: choice of a labeling process, choice of an initialization, tuning of the size of the loops, etc.
However, when they talk about Active Learning, the majority of people refer to “uncertainty-based” Active Learning, and in particular, to the least-confidence querying strategy. The issue is, while this approach is popular, it often does not lead to optimal results, and unfortunately, they often interpret the fact that this particular approach had not worked out for them as a fact that Active Learning is not going to yield good results for their use case, or worse, that Active Learning just doesn’t work. This isn’t without similarity with the frequent claims that Deep Learning was a fad when Deep Learning was still in its infancy.
We cannot emphasize enough here that there isn’t a simple way to set up an Active Learning process, and that how it is set up will make all the difference between an entirely biased model and a resounding success.
So today, let’s dive into the least-confidence querying strategy. Our goal is to explain how it works but also what its shortcomings are.
Setting up the context
This time, we are going to use a toy example to illustrate what happens when using a least-confidence querying strategy, and we have chosen the Quickdraw dataset to do so.
The Quickdaw dataset is a really fun collection of 50,000,000 doodles drawn by players of a mini-game called “Quick, Draw!” released by Google a few years ago. In the context of the game, the players were given 30 seconds to draw an object (such as a car or an animal) well enough that the algorithm would be able to guess what the object is. It was essentially a human-vs-computer version of the famous Pictionary game. Google’s genius was to use the drawings themselves as training data to improve the algorithm, and eventually, they open-sourced the dataset.
Here, we are using the Quickdraw dataset as an alternative to CIFAR-10 or ImageNet because we believe that it outlines that annotating data isn’t as trivial as people often think. Of course, in the context of Quickdraw, the dataset is annotated since the images are drawn based on the word provided, but in a real-life use case, we would have unannotated images that need to be labeled as they get selected.
For this tutorial, we will assume that we are running a classification Computer Vision model on a subset of 3 classes: Monkey, Octopus and Rabbit.

Figure 1: a sample of the Rabbit class taken out of the Quickdraw dataset
How the least-confidence querying strategy works
In order to move further, you will need a basic understanding of the Active Learning process and the related jargon which you can find here.
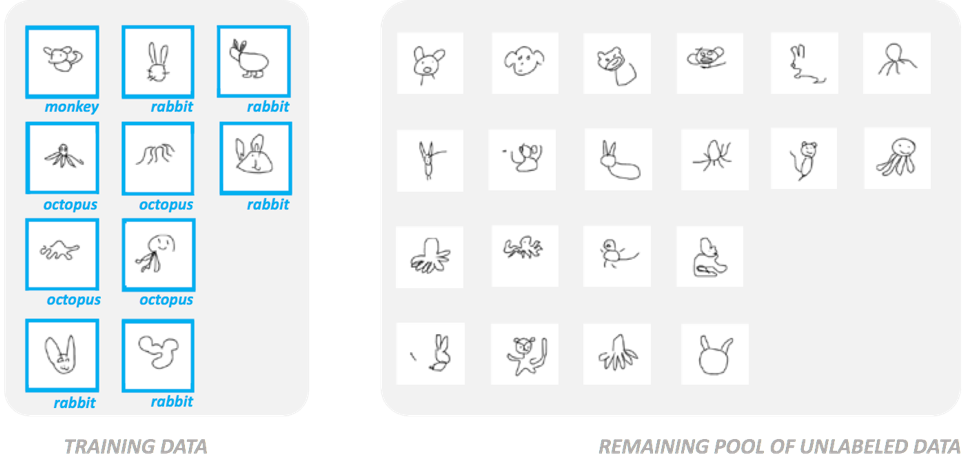
To initiate the process, we will need to select some data from a pool of unannotated data. The problem is that we have little to go by for now: the initial pool of data is nothing more than a list of records, and each one of them can either be a monkey, a rabbit or an octopus but we don’t know which because for now, it’s not supposed to be labeled.
This is the initial pool of unannotated data:

Figure 2: a pool of raw, unlabeled data from which a training set has to be selected before being annotated
Some of the records are monkeys, some are octopuses, and some are rabbits, but at this point, there is no telling which one is which.
SELECT STEP: For the first loop (at Alectio, we call it loop #0 before it’s basically a shoot in the dark), some data gets randomly picked. Optionally, the data scientist can also decide to cluster the data to ensure some diversity in the picked sample, in particular to avoid that all selected samples fall under the same class.

LABEL STEP: Now that some records have been selected, they need to be annotated before they can be used for training. How they get annotated (or by whom) is irrelevant to the vanilla case of Active Learning, but it is obviously best to have the highest labeling accuracy possible. If one of the (actual) monkeys is labeled as something else, it could have dramatic consequences on the learning process, especially this early.

TRAIN STEP: The selected data can now be used as training data; the initial dataset is now split into two parts: an annotated dataset, and a pool of remaining, unannotated data which we can pick from next.
Up to the stage, the steps remain the same regardless of the querying strategy, keeping in mind of course that we had the option to choose our annotation process and the way we wanted to initialize the process.

INFER STEP: This is where it gets interesting: now that we have a trained (though probably very inaccurate) model, we are going to use it to run predictions on the unselected data. It’s a little as if we were using the rest of the pool as a validation set – with one very important exception: without annotations, we cannot evaluate whether those predictions are correct or not. So while it would be tempting to just select the records for which wrong predictions were made, we need another proxy to find interesting data.

The most straightforward approach researchers thought about? Using the confidence score of the prediction as that proxy. The issue? We will talk about it at the end.
The entire logic of the least-confidence querying strategy goes as follow:
- Generate predictions alongside their confidence score for every single remaining record in the unselected data pool
- Select the N records with the lower confidence scores, where N is the loop size. This is already the SELECT step of the next loop.

The unselected pool has now shrunk, while we have grown our training dataset.
The entire process is based on the fact that if the model generates predictions with a low confidence score, it means it is unsure of that prediction and that it would benefit from some validation / reinforcement. Simple but effective. Also, unfortunately, insufficient under many circumstances, but you get the idea. The least-confidence querying strategy belongs to a category of querying strategies called “uncertainty-based” querying strategies (but if you want to read more about them and other querying strategies, you can read all about them in this other blog post).
So what’s the issue with the least-confidence strategy?
At first, the least-confidence looks like a very smart approach, and frankly, it can be very powerful in many circumstances. However, there are lots of situations where it can fail miserably, and here are the top reasons why.
Some models are terrible at self-evaluating
The confidence score itself is generated by the model (how exactly it depends on the algorithm). Therefore, just in the same way that the predictions themselves can be wrong, there is also no guarantee that the confidence scores are reliable.
In fact, in the case of Deep Learning models, researchers have demonstrated that deeper architectures were typically leading to higher average confidence scores, and that the mean confidence scores were typically higher than the average accuracy. In short, larger models tend to overestimate their own accuracies. This leads to confidence level to be generally less reliable, and can lead to problems when basing a querying strategy on the very concept of self-reported confidence.
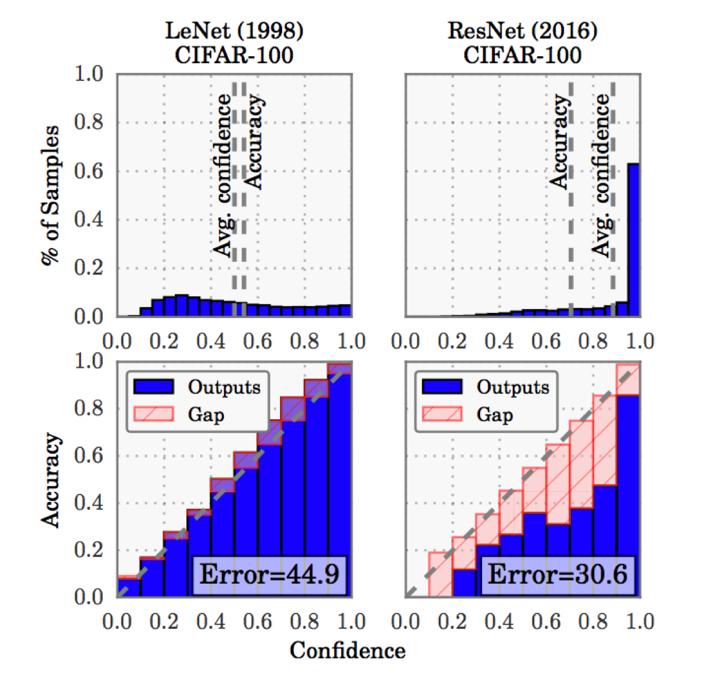
Figure 3: the figure above, taken from the article “On Calibration of Modern Neural Networks” shows how the average confidence score of predictions generated by a larger model such as ResNet, tends to exceed its accuracy, while the average confidence scores for a smaller model such as LeNet tends to be lower than its accuracy. This result demonstrates how model-dependent confidence scores can be, and hence, how using them for secondary applications could lead to serious issues.
The approach assumes that focusing on novelty is the right thing to do
The entire strategy is based on the assumption that models would benefit from seeing more “difficult” or contentious examples. We’re basically saying that if the model feels confident about something it just learned, chances are that it is more likely to be right, and it is a better use of resources to focus on something else, just like we would with a human learner. However, just like with humans, constantly focusing on newer, more difficult concepts can lead to confusion. No teacher would ever think it is a good idea to show new words only to a student learning a new language: some reinforcement of existing knowledge is generally necessary if you want to guarantee that the student doesn’t forget what he/she already knew.
Sometimes, low confidence is just tied to bad quality
Imagine that some of the data either doesn’t belong in the dataset, or is just of very poor quality. This would happen if you train an english-based NLP model with a training set that contains some foreign data. It would then be inevitable that the foreign-language examples would just trigger low confidence scores, and selecting the low confidence examples would cause us to do the opposite from what we want them to do: we would actually pollute the dataset with bad data instead of selecting useful records.
Confidence is just one “feature” to consider
As discussed previously, the confidence score is used as a measure of usefulness. However, if there is one thing that data scientists know, it is that models need multiple features to be accurate. No one has ever expected a model to make accurate predictions with a simple feature as an input, so it is almost weird to think that someone would expect a querying strategy with only the confidence score as an input to successfully select useful data. Therefore, while confidence can definitely be a highly predictive “meta-feature” to measure the interestingness of a record, it should not be considered as sufficient on its own.
It’s just a rule-based approach anyways
Finally, like all off-the-shelf querying strategies, the least-confidence strategy is a pre-established, arbitrary rule set by the human putting the process together. It is just like a hyperparameter in Deep Learning: there is a reason why an expert might feel it is a good idea to use it (based on their experience with similar models and datasets before), but there are also many reasons why their know-how might not be relevant to a given use case. It is for the same reason that hyperparameter tuning techniques have been invented and usually over-perform humans.
*********
At this point, you probably understand that the least-confidence strategy is just one of many approaches that can be used to select data, and that while it is overall a very clever idea, it can easily fail or lead to unsatisfactory results. Each model and dataset requires a differently tuned approach, and there is no reason to believe that the least-confidence strategy is a silver bullet. Overall, it is important to understand that the fact that this particular sampling method doesn’t work on your model and/or use case doesn’t mean another one will not work – and certainly not that Active Learning as a whole doesn’t work for you. Be patient, learn about other strategies and keep in mind that ultimately, an Active Learning process needs to be tuned the same way as a model does.



0 Comments