
With ever more conversations about Data-Centric AI, the number of posts and articles discussing Active Learning has grown exponentially over the past few months. Yet, quite paradoxically, the level of confusion about the topic has never been higher. From the product executive who believe Active Learning to be synonym for ML Observability (the part of MLOps concerning itself with the retraining of Machine Learning models when data drift is detected) to the Machine Learning influencer who misguides his followers by explaining that Active Learning allows them to get data annotated for free, it seems like even the experts are confused.
We’ve decided to write this short piece with the intention of setting things right once and for all. If you want to understand what Active Learning is all about once and for all, this is all you’ll ever need to read.
What Active Learning is NOT
One of the top sources of confusion about Active Learning is that the term has been used loosely for many years. Over time, it got confused with Human-in-the-Loop Machine Learning, Semi-Supervised Learning, Self-Learning, Auto-Labeling and even Reinforcement Learning. However, Active Learning has a strict technical definition as well as its own field of experts who have dedicated their careers to furthering the technique.
For that reason, before we explain how Active Learning works, let’s start by what it is not:
- Active Learning is not an alternate term for Semi-Supervised Learning. However, it is a Semi-Supervised Learning technique, which by definition means that it leverages partially labeled dataset. In other words, it helps you avoid annotating the entire dataset.
- No matter what you have heard, Active Learning on its own is not going to get your data annotated. The tagline “Get your dataset annotated with Active Learning” just doesn’t make sense. Active Learning can do wonders to help annotate data faster, but it won’t actually generate annotations.
- Active Learning is not a model or an ML algorithm. It is a training paradigm which can work with virtually any type of Machine Learning algorithm. Your random forest or your deep learning model can each actively learn. In fact, Active Learning can even be paired with other paradigms, like Transfer Learning, so there is actually such a thing as Transfer Active Learning.
- Active Learning isn’t a silver bullet. You cannot just say “Active Learning doesn’t work”. In that sense, it’s a bit like Deep Learning: it requires experience to tune an Active Learning process and if it doesn’t work for you, it might mean that your dataset haven’t reached the critical mass necessary to see the benefits, or just that you haven’t found the right querying strategy yet (we’ll explain what a querying strategy is in a minute!)
Why does Active Learning exist?
Active Learning was invented because sometimes, ML experts could not get the entire dataset annotated, either because of a lack of subject matter experts on the market, or because annotating the entire dataset would be too slow or too expensive. It gained popularity in Academia because academic researchers were often more cash-constrained as their industry counterparts (you can read more about Active Learning actually did not become popular in the Industry yet here).
The idea behind Active Learning was to dynamically uncover which training records were most likely to boost the model’s performance; in a sense, Active Learning is about prioritizing the most valuable data, and hence, actually has potentially more applications than just reducing the amount of labels required.
But enough with context-setting for now, let’s get started with the code of the subject:
How does Active Learning work?
Good news!!
If you have:
- a Machine Learning model ready-to-train
- and an unannotated dataset,
then you have all you need to start experimenting with Active Learning.
The first thing to understand about Active Learning, is that it takes a cyclical approach to learning, which requires to retrain the same algorithm with increasingly more training data picked from the original pool of unannotated data.
Each one of those cycles is called “a loop”, and it follows a succession of the same 4 steps:
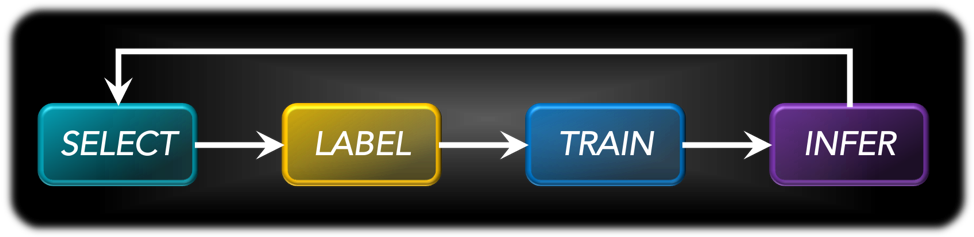
- The SELECT step is referred to as “querying strategy” or “selective sampling”. It uses the knowledge of what happened during the previous loop (or loops, since Alectio has developed proprietary multi-generation querying strategies that look at what happened in all past loops) to decide what data to select next from the unannotated pool of data (which, obviously, shrinks over time).
In the traditional forms of Active Learning, those querying strategies are “dumb”: they are simply pre-established, rule-based algorithms that are applied on the output of the INFER step from the previous loop. They’re also typically static, which means the rule remains the same through the entire process, but there is of course no true reason why those querying strategies wouldn’t “evolve” or even be ML-driven processes in their own right.
The SELECT step for the first loop is of course the trickiest because there is no past knowledge to rely on, so either the initial loop is generated randomly, or paired with an unsupervised approach that helps maximize the diversity of the selected sample.We have written another blog post specifically about querying strategies if you want to learn more.
- After some data records are selected as “worthy of interest”, they need to be annotated before they can be fed into the model as training data: that’s the How it gets annotated is irrelevant: you can annotate it yourself, use a labeling company, an auto-labeling approach or even the popular Snorkel algorithm. However, you better make sure the annotations are correct if you want to ensure the process isn’t biased.
- Now that you selected additional data from the initial pool, and that those records are annotated, it’s time to retrain the model: this is the TRAIN step. This means that at each loop, the model is being retrained with more data, and in the case of Deep Learning, this might mean that some additional hyperparameter tuning might have to be done (for example you might need a large number of epochs in later loops to avoid underfitting).Most practitioners choose to reinitialize the model and retrain and all data selected so far, at each loop. It means that if 1,000 records are selected at each loop, then the model will be trained with 1,000 records during the initial loop, 2,000 records for the second loop, etc. And that might blow up the compute bill (read more here).
- Once all those steps are complete, you’ll have a newly updated model, hopefully better than the one trained at the previous loop. There is no guarantee of that happening though, as you might have selected corrupted data or used mislabeled data.
The last step is to now apply this new model to infer on the rest of the unannotated pool. Which means that if you have selected 5,000 records out of an initial pool of 100,000 records, you need 95,000 inference operations.
This INFER step will not only generate predictions for each remaining record, but also meta-information, such as new parameter states, confidence scores, etc. All this meta-information is then fed into the next SELECT step as an input.
And there you have it: this is what Active Learning is: nothing more, nothing less.
As you can see, many different approaches can be chosen for each one of those steps:
- Active Learning makes no assumptions about how the querying strategy (the SELECT step) is picked or designed; in fact, it doesn’t even prescribe that the same querying strategy is picked at each loop
- How many records are picked at each loop is totally up to the person who sets the process, and just for querying strategies, there is no strong reason why the loop size should remain the same. You’re kind of dealing with a balance between precision (making sure that the selected records will actually help) and cost-control (the more loops, the higher the compute costs). Loop size is actually a hyperparameter that needs careful tuning.
- Whether the process gets aborted early, is also up the user
- There is no “right” way to initialize an Active Learning process, and the initialization can bring a lot of “randomness” down the line. So again, different people proceed differently.
- Whether the parameters are cleared at each loop is also a choice that’s left to the user.
- Pretty much any technique (human-driven or machine-driven) can be chosen to get the selected data annotated and the labels validated. Technically, Active Learning doesn’t need to rely on human-labeling. If you were to choose to annotate the data by using a separate Machine Learning model, then none of the steps would require human intervention, which makes Active Learning completely separate from Human-in-the-Loop Machine Learning.
What we hope you retain from this read
How you tune your Active Learning process is 100% up to you, and there are countless ways to do it.
- Your querying strategy does not need to be confidence-level based.
- Your loop size doesn’t need to be static.
- You’ll have to annotate the selected data, and you’ll have to choose how to generate those annotations.
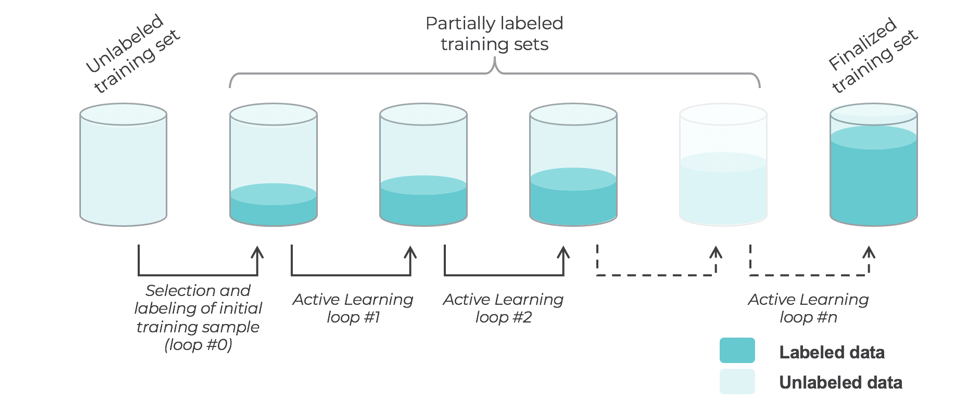
Overall, Active Learning is an approach that relies on incremental retrainings of a Machine Learning model designed to grow and groom high-performance training data from a raw pool of data. Becoming an expert on how to best tune that process requires patience and practice, and if that’s your goal, we invite you to navigate our blog and follow us on social media, as we have plenty more content for you to learn from.



0 Comments
Trackbacks/Pingbacks